
CyberRt源码剖析--05基于共享内存的通信实现
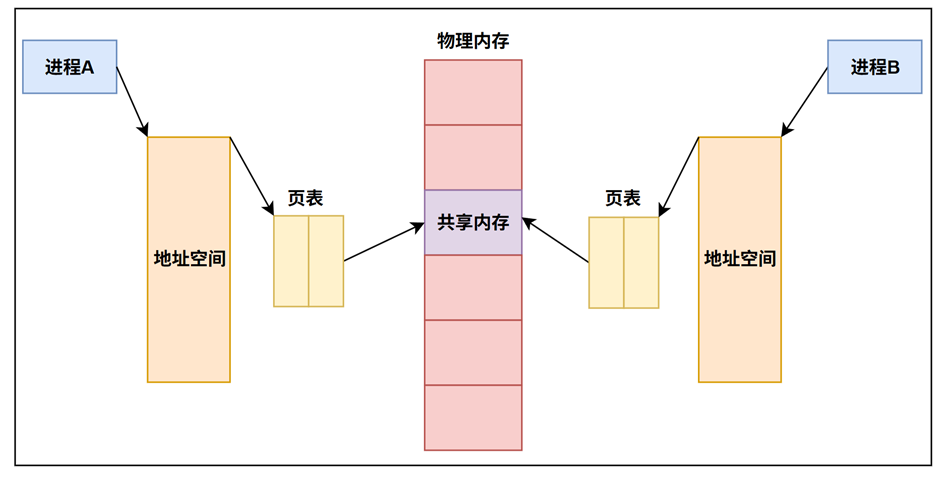
5.1 什么是共享内存
共享内存(Shared Memory)是操作系统层面实现高效进程间通信(Inter-Process Communication, IPC)的关键机制,其核心设计理念在于突破传统进程间内存隔离的限制,使多个进程能够直接访问同一物理内存区域,从而显著提升数据传输效率并减少通信过程中的数据复制开销。
5.2 CyberRT共享内存通信模型
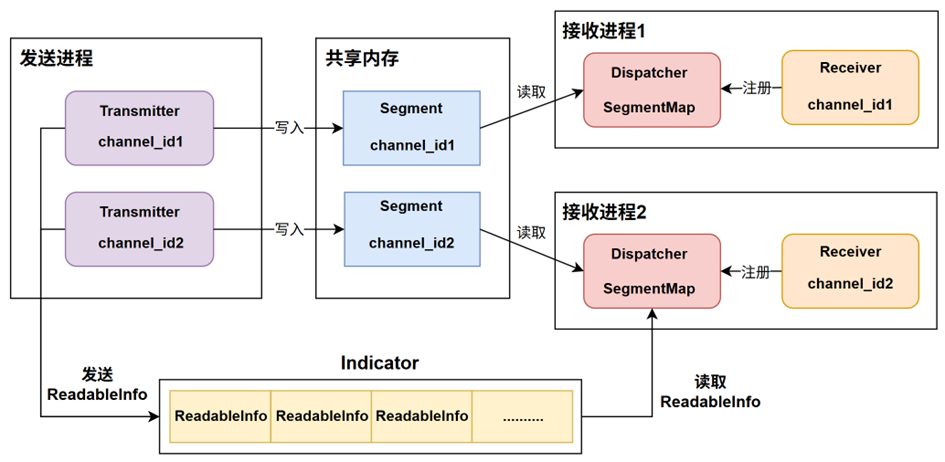
发送进程中的Transmitter在发送数据时会绑定一个确定的channel_id,同时根据此channel_id去创建一片共享内存,这片共享内存被定义成一个Segment。接收进程中的Receiver也会存在自己所关注的channel_id,在接收进程设计了一个SegmentMap:<channel_id, Segment>的数据结构,SegmentMap保存了channel_id和对应共享内存Segment之间的索引关系,Receiver在获取对应channel_id上的数据时会首先向SegmentMap中注册,后续获取数据通过去SegmentMap根据channel_id找到Segment从而拿到数据。Transmitter在向一个Segment写入数据后会发送通知信息代表自己已经将数据写入完毕,Receiver可以从此Segment中拿到数据。通知信息被定义为ReadableInfo,在同一主机中会专门创建一块名为Indicator的共享内存用于存放这些通知信息。在接收进程中Dispatcher用于监测是否有Segment上的数据被更新写入了,Dispatcher内部会有一个单独的线程不断的去遍历读取Indicator上的通知消息来判断是哪个channel_id上的Transmitter发送了数据,即如果发送进程的Transmitter向其channel_id对应的Segment写入数据了则Dispatcher会实时监测到将数据分发给订阅者。
5.2.1 Segment定义
Segment的内存结构定义如图所示,每个Segment共享的内容有:一个State、n个Block、n个Buffer、一个Unused。State控制的是当前Segment进程间的共享状态;Buffer储存了Transmitter发送的每条数据;Block控制了Buffer的读写状态;Unused为未使用内存区域,设置为冗余内存。
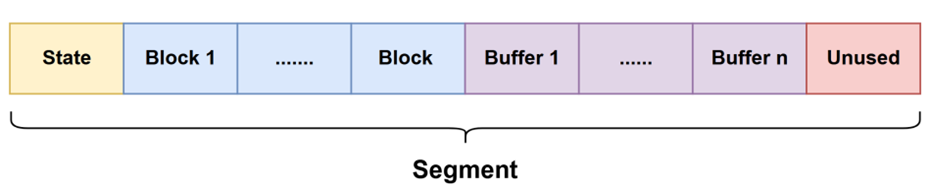
一个Segment的内存占用大小是和想要传递的消息数据大小息息相关的。具体地,比如假设传递的一条消息的大小在10kb~100kb,则对应第2条规则,首先规则中定义了每个Block的大小为1024字节,一个Segment中Block个数为128,buffer的个数也对应为128个,一个buffer由两部分组成:承载消息的Message和额外的MessageInfo。MessageInfo的大小固定为1024个字节,因此此时一个buffer的大小就是128kb+1kb =129kb。除此之外规定Segment头部的State的大小为1024字节,Segment的尾部未使用的部分占用的大小为1024*4=4kb。
| 消息大小 | Block数量 | Buffer数量 | 消息占用内存(字节) |
|---|---|---|---|
| 0~16k | 512 | 512 | 1024*16 |
| 16k~128k | 128 | 128 | 1024*128 |
| 128k~1M | 64 | 64 | 1024*1024 |
| 1M~8M | 32 | 32 | 102410248 |
| 8M~16M | 16 | 16 | 1024102416 |
| 16M~32M | 8 | 8 | 1024102432 |
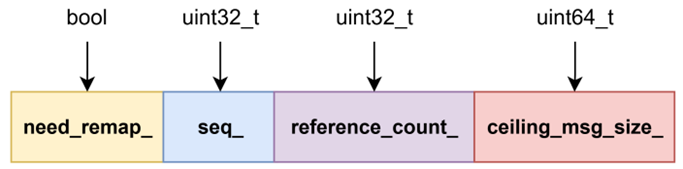
State由四个原子变量组成,need_remap_用于控制当前的Segment是否需要重新映射,ceiling_msg_size_代表消息数据的大小即一个Buffer的字节数,从上面的规则可以看出,如果数据消息越大,那么Segment维护的队列长度越短。seq_代表的是当前正在写的Block的索引,Transmitter每发送一条消息就会去写入一个Block和一个Buffer,每次写完数据后就会将seq+1,reference_count代表使用这片内存的用户的个数。
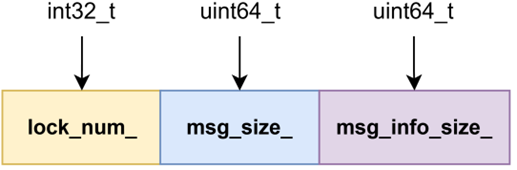
Block由三个原子变量组成,,lock_num_用于控制Block对应的那个buffer的读写互斥,用于做到进程间的安全读写,msg_size__和msg_info_size_代表着消息的长度。
5.2.2 Indicator定义
为了实现多进程间各发布者和订阅者之间的消息通知机制,创建了一个特殊的数据结构Indicator,当第一个发布节点启动后则会去开辟一块全局唯一的共享内存用于存放Indicator。此Indicator是同主机上所有发布者和订阅者共享的

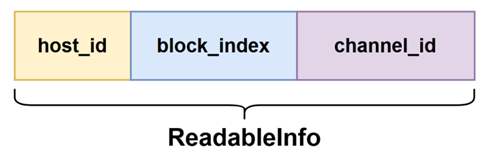
Indicator为一个队列形的数据结构,可存储4096个ReadableInfo,每个ReadableInfo会对应一个索引,此索引会被写入到Indicator尾部的seq数组中,因此seq数组的大小也为4096。头部的next_seq是一个原子变量代表着下一个可写的ReadableInfo的索引,host_id为每个主机的唯一标识;channel_id 即代表发布者向哪个channel_id上的Segment写入数据;block_index即代表着写入数据的Segment的block索引。
5.3 基于共享内存的发布方实现
通信架构中ShmTransmitter会实现基于共享内存的发布方,其软件架构如图所示。根据通信流程可知,ShmTransmitter会向一个channel上写数据,并且写入的数据结构类型也是发送方事先确定好的,每个channel会对应一个Segment,因此ShmTransmitter在发布数据时会先去根据要发布的数据结构的类型和大小根据上述的规则去创建一片Segment,即在重载的Enable函数中会根据当前Transmitter的channel_id去新建一块Segment,Segment为一片全局的共享内存,在linux环境下有两种方式来创建共享内存,分别是基于System V IPC和 POSIX IPC,使用这两种方式都可以。
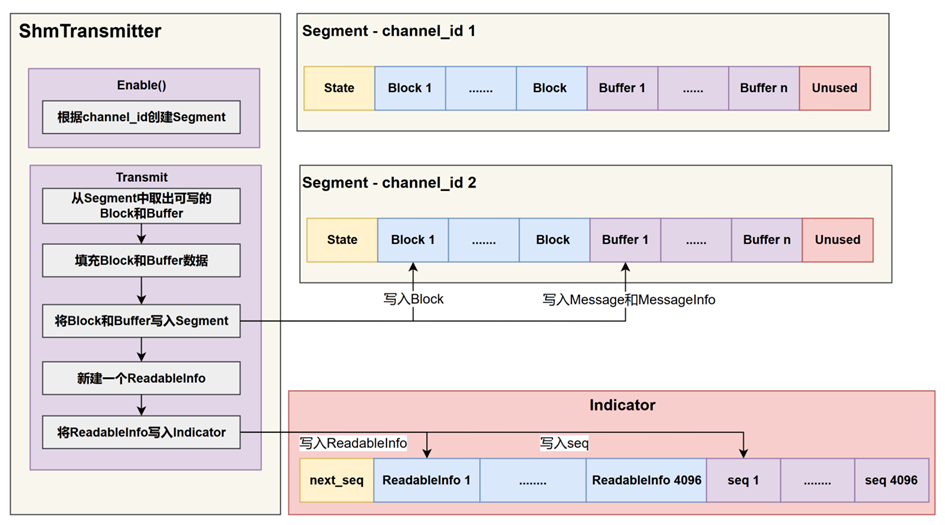
在创建完毕Segment后就可以往这片Segment上写入数据了,通过Transmitt函数来实现。数据写入的目标是向Segment中的其中一个Block和对应的Buffer填入数据,因此需要事先拿到一个Buffer的索引,而State的seq_就记录了该索引。State中的seq_初始值为0,每一次获取可写的Block索引时都会将seq_的值增加1,如果seq_的值超过了当前Segment的Block的数量,则从头轮转,即使用取余操作,使得seq_的值限定在0和Block的数量数量之间。同时获取可写的Block索引这步操作是一个循环操作,只有在确定拿到的这个Block的索引对应的Block是可写的才会将此索引返回从而跳出循环操作。Block是根据头部的lock_num_来进行读写互斥的,lock_num_是一个原子变量,初始值为0,因此对此变量的读写是进程安全的,假设当前的Block是可写的,那么会去原子性的判断ock_num_的值是否为0,如果为0,则将lock_num_的值置为负数,代表有一个进程已经占用了此Block,如果此时有另外一个进程也想来对此Block进行写入,则先判断lock_num_的值发现为负数,则不可被此进程进行写。
通过上面的操作就能从Segment中去拿到一个可写的Block和对应的Buffer,接着就是向此Block和Buffer写入数据,当写入数据后需要释放对此Block和Buffer的独占所有权,这里就是将此Block的lock_num_的值重新置为0,说明没有进程在对此Block写入数据了。
当ShmTransmitter向一个channel_id上的Segment中的某个Block和Buffer上写入完毕数据后,接着需要填充一个ReadableInfo,因此首先需要向Indicator中请求,此时全局的Indicator头部的next_seq就是可写的ReadableInfo的索引,发布者写入ReadableInfo之前会将next_seq原子性的增加1,然后再向拿到的索引处写入通知信息。
订阅者进程中会不断读取Indicator上的ReadableInfo的信息进行数据分发,具体来说内部会单独启用一个线程,此线程的主体为一个无限循环的函数,内部会单独保存一个本地的seq索引,初始值为0。线程循环函数会循环读取Indicator头部的next_seq的值和本地的seq进行比对,如果next_seq的值不等于本地的seq则说明由其他发布者发布了数据并且写入了ReadableInfo,此时就可根据本地保存的seq去Indicator索引seq数组,然后将本地的seq更新为seq数组中的值,接着就可去拿到本地seq对应的ReadableInfo,最后比对channel_id判断当前发布者进程是否包含此channel_id的订阅者,如果存在则根据channel_id去索引Segment,然后根据ReadableInfo中的block_index去把发布者写入的数据读取出来。
5.4 基于共享内存的订阅方实现
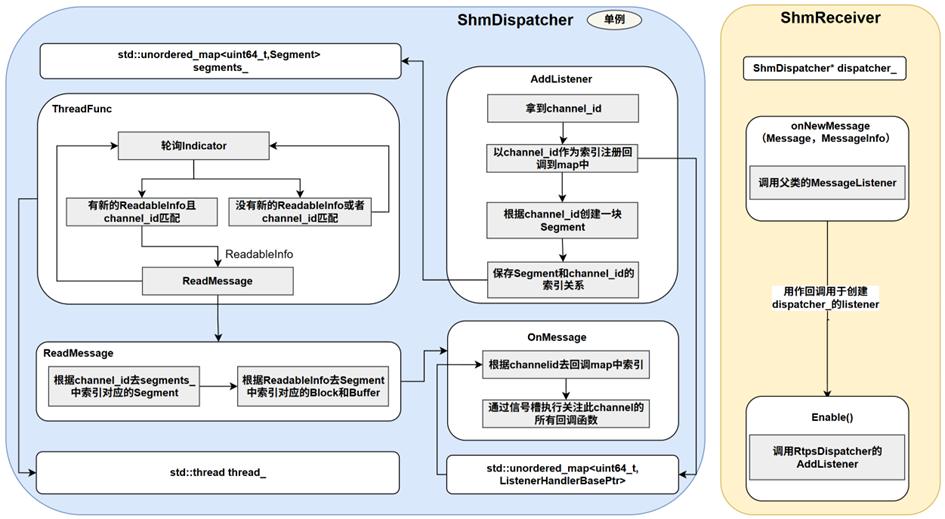
基于共享内存的数据订阅方由ShmReceiver与ShmDispatcher联合实现,具体设计如图所示,ShmReceiver的实现和RtpsReceiver类似,会把传入ShmReceiver的回调函数进行打包后然后调用ShmDispatcher的AddListener函数。在ShmDispatcher中定义了SegmentMap:<channel_id, Segment>,用于保存channel_id和Segment的索引关系,在AddListener函数中会根据ShmReceiver的channel_id去创建一块Segment,创建完毕后就会将索引关系注册到SegmentMap中。在ShmDispatcher中单独创建了一个独立的线程thread_,此线程的执行主体为ThreadFunc函数,在ThreadFunc函数内部会不断地轮询Indicator去获取ReadableInfo,如果有ShmTransmitter发送了数据则就会往Indicator中写入一条新的ReadableInfo,此时会被ThreadFunc捕捉到,如果此ReadableInfo的channel_id能在SegmentMap中查找到则说明是当前进程的ShmReceiver订阅的。随后将读取到的ReadableInfo传递给ReadMessage函数处理,在ReadMessage函数中会取出对应的Segment,再从此Segment中取出Block和Buffer,最后将Buffer中的Message和MessageInfo传递给OnMessage函数,最后通过信号槽机制执行回调处理。
在通信中间件框架中,拓扑机制是实现网络节点互联管理的核心组成部分,其设计目标在于确保分布式系统中节点加入或退出时,网络能够动态调整并维持通信的连贯性与一致性。拓扑结构本质上是网络中各站点互联形式的抽象表达,在本文设计的通信中间件中体现为:当一个新节点加入通信平面时,其他节点通过广播机制感知其存在并更新全局拓扑图。新节点可能扮演发布者或订阅者的角色,在正式参与数据交互前,需广播其属性信息,以便网络中的其他节点据此建立连接。然而,如何高效地表示和管理这种动态的节点关系,是拓扑机制设计的关键问题。
在分布式系统中,节点间的通信关系具有方向性(例如从发布者到订阅者的数据流)和动态性(节点可能随时加入或退出),这对拓扑表示方法提出了较高要求。有向图作为一种经典的图论模型,能够以O(V+E)(E为边数)的空间复杂度高效表示稀疏网络,同时通过邻接表或边列表结构支持节点的动态增删操作。此外,有向图天然支持方向性关系的表达,能够清晰刻画发布者到订阅者的单向数据流,符合发布-订阅架构的通信特性。因此,本文选择基于有向图构建拓扑机制,以充分利用其在表示复杂网络关系、支持动态调整及优化查询效率方面的优势。
在具体实现中,本设计通过有向图抽象分布式系统中节点间的通信关系,其中顶点表示通信实体,有向边表示数据流方向(如从发布者到订阅者的Channel连接)。当新节点加入时,其属性信息通过广播分发,其他节点据此更新本地拓扑图,从而实现网络的自适应调整。以下将从角色定义、底层数据结构及动态管理三个方面,详细阐述该机制的设计与实现。
 微信
微信 支付宝
支付宝
![ARM64-Trust-Firmware[3]-BL1解析](/2026/01/24/ARM64-Trust-Firmware-3-BL1%E8%A7%A3%E6%9E%90/17692290470595.png)
![ARM64-Trust-Firmware[2]-启动ATF](/2026/01/24/ARM64-Trust-Firmware-2-%E5%90%AF%E5%8A%A8ATF/17692287555201.png)
![ARM64-Trust-Firmware[1]-ARM安全架构](/2026/01/24/ARM64-Trust-Firmware-1-ARM%E5%AE%89%E5%85%A8%E6%9E%B6%E6%9E%84/17692284856153.png)
![Xhyper剖析[6]--中断虚拟化](/2026/01/20/Xhyper%E5%89%96%E6%9E%90-6-%E4%B8%AD%E6%96%AD%E8%99%9A%E6%8B%9F%E5%8C%96/17689244713913.png)
![Xhyper剖析[5]--MMIO虚拟化](/2026/01/20/Xhyper%E5%89%96%E6%9E%90-5-MMIO%E8%99%9A%E6%8B%9F%E5%8C%96/17689243819381.png)