
CyberRt源码剖析--07协程调度框架
7.1 什么是协程
协程的核心在于将程序的执行流程划分为多个可控的片段,每个片段能够在特定时点暂停或恢复运行。这种机制通过协作式调度实现,开发者可在代码中显式指定挂起和恢复的时机,从而避免传统线程因抢占式调度带来的复杂同步问题。协程的生命周期包括以下四个阶段:
1.创建(Creation):协程通过特定的语法或函数被创建,此时协程处于就绪状态,等待被调度执行。
2.挂起(Yield):协程在执行过程中可以主动或被动地暂停执行,将控制权交还给协程调度器。挂起操作通常在等待 I/O 操作、等待其他协程完成或主动让出 CPU 时发生。
3.恢复(Resume):协程调度器可以在适当的时候恢复协程的执行,从上次挂起的位置继续运行,直到完成任务或再次挂起。
4.销毁(Destruction):当协程完成任务后,会被销毁并释放占用的资源。
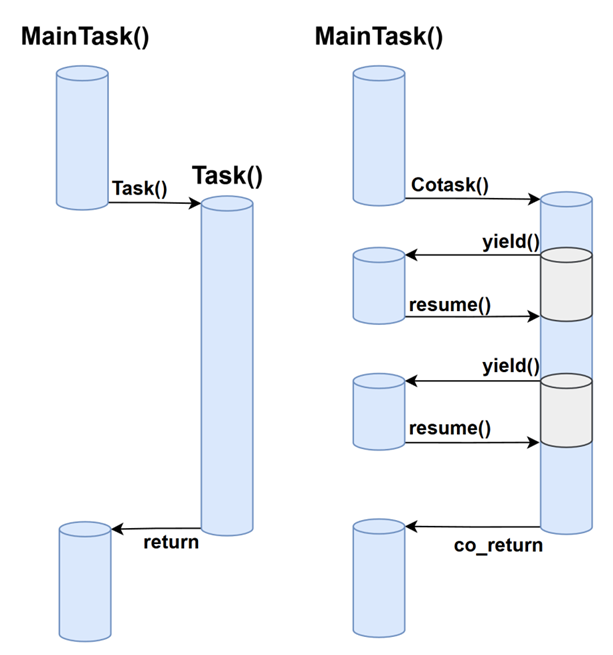
- 如上图左边假设一个
MainTask是一个线程去调用Task()函数去执行一个功能,如果Task()是一个普通函数,那么MainTask会等待Task()执行完毕返回后继续执行MainTask的步骤 - 如上图右边如果
MainTask去执行Cotask(),而Cotask()是一个协程,Cotask()在执行的过程中可以通过yield()或者await()这样的函数暂停自己的执行,并且返回到MainTask继续执行,而主函数也可以调用resume()这样的函数重新回到Cotask()这个协程执行,并不会像函数那样必须执行完毕才返回。这样就做到了用户态的并发,一个线程里可以存在多个协程,并且可以提供一个协程调度器来调度这些协程进行执行。 - 协程实现的关键在于如何在协程切换的时候能够保存当前的执行信息,并且在切换回当前协程时能够恢复执行状态继续往下执行
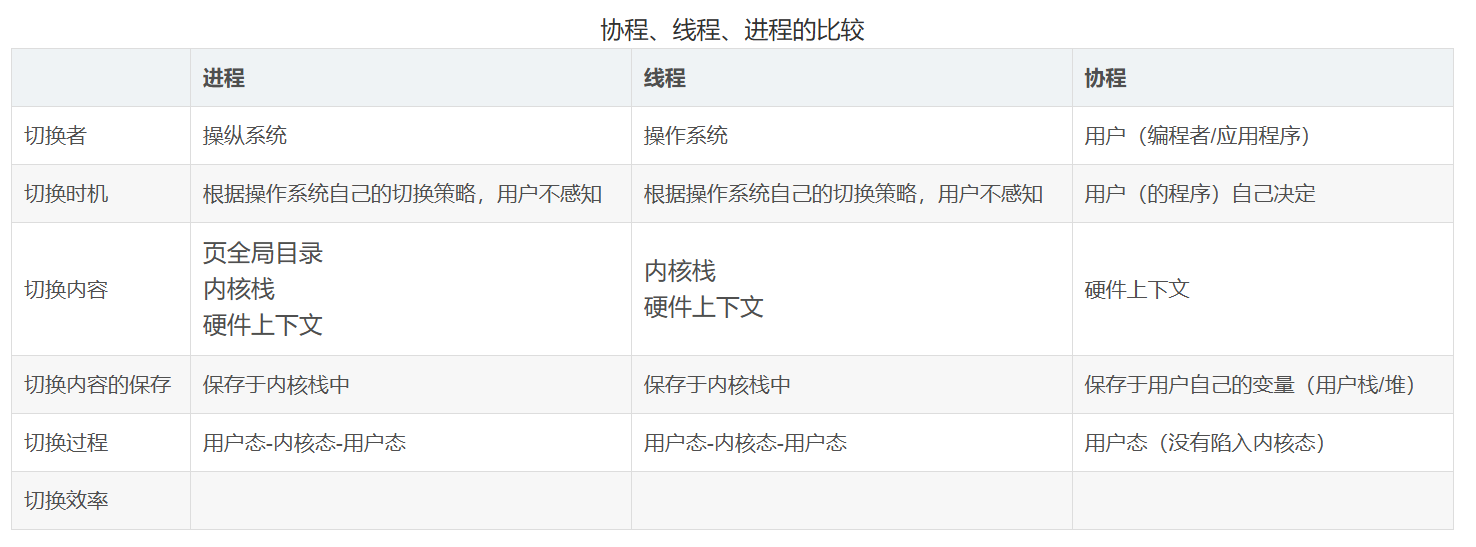
- 相比于线程,线程是操作系统调度的最小单位,每个线程都会占用cpu时间片,同时需要切换线程上下文,协程在用户态切换,带来的开销会小很多,当然协程只是并发并不是并行。
7.2 协程框架的设计
7.2.1 协程栈管理
实现的协程为有栈协程(Stackful Coroutine),即每个协程拥有独立的栈空间。与无栈协程(Stackless Coroutine)相比,有栈协程能够更灵活地支持复杂的函数调用和上下文保存,尽管其内存开销稍大。为单个协程执行分配的栈空间大小为2MB,这一容量足以容纳协程运行所需的上下文信息,包括函数调用栈、局部变量和寄存器状态。协程上下文的具体内容因CPU架构而异,针对当前主流嵌入式和服务器平台,实现了AArch64和x86_64两种CPU架构下的协程设计。以x86_64架构为例,具体讲解协程框架的设计与实现细节。
| Register | Usage | Callee saved |
|---|---|---|
| rax | 临时寄存器;在可变参数情况下,传递有关使用的向量寄存器数量的信息;第一个返回寄存器 | No |
| rbx | 被调用方保存的寄存器 | Yes |
| rcx | 用于向函数传递第四个整数参数 | No |
| rdx | 用于向函数传递第三个参数,第二个返回寄存器 | No |
| rsp | 栈指针 | Yes |
| rbp | 被调用方保存的寄存器,可选择用作栈帧指针 | Yes |
| rsi | 用于向函数传递第二个参数 | No |
| rdi | 用于向函数传递第一个参数 | No |
| r8 | 用于向函数传递第五个参数 | No |
| r9 | 用于向函数传递第六个参数 | No |
| r10 | 临时寄存器,用于传递函数的静态链指针 | No |
| r11 | 临时寄存器 | No |
| r12~r14 | 被调用方保存的寄存器 | Yes |
| r15 | 被调用方保存的寄存器,可选择用作全局偏移表基指针 | Yes |
| r16~r31 | 临时寄存器 | No |
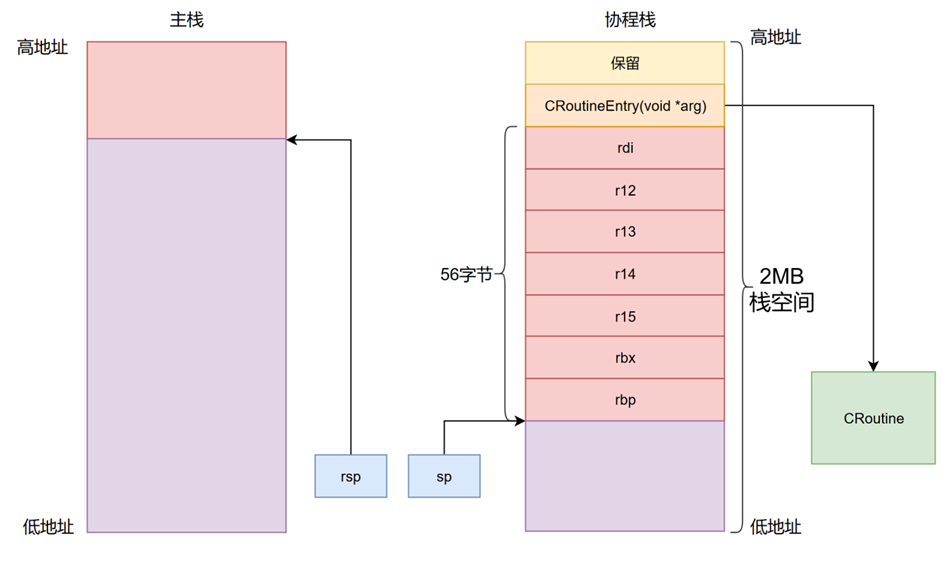
根据x86_64的应用程序二进制接口(ABI)规定,如表所示,在进行函数调用时,被调用者(Callee)需要保存rbx、rbp、rsp、r12、r15总共7个寄存器。这些寄存器在函数调用链中起到关键作用,例如rbx和r12、r15用于保存长期使用的变量,rbp作为栈帧指针,而rsp则维护栈顶位置。协程的本质是一个特殊的函数,其切换过程本质上是对函数执行流的控制,因此在进行协程切换时,也需要将这7个寄存器保存到协程栈中,以确保切换后协程能够正确恢复执行状态。在CyberRT的设计中,rsp寄存器由于其特殊性(直接影响栈操作),被保存在额外的独立空间中,而rdi寄存器则因需要传递参数(例如协程初始化时的入口函数指针)而被一并保存至栈中。每个寄存器占用8字节(64位架构下),因此协程栈中需要56字节的空间来存储这些寄存器相关信息。此外,考虑到实际应用中可能涉及更深的调用栈和额外的局部变量,2MB的栈空间设计既保证了足够的余量,又避免了过度的内存浪费。
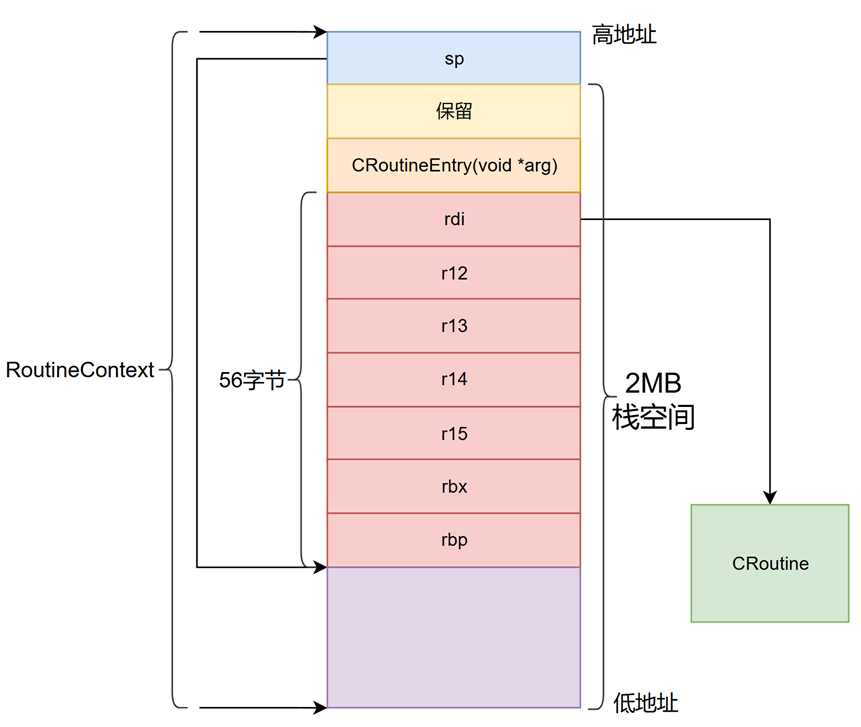
基于上述对协程栈的需求,设计了RoutineContext结构来代表协程栈空间,并额外设置了一个sp变量用于指向协程栈的栈底位置。这一设计便于在切换时快速定位栈底并恢复上下文。RoutineContext会在创建协程之前进行初始化,其初始化过程如图所示。在初始化RoutineContext时,首先将rdi寄存器指向一个名为CRoutine的模块,此CRoutine是与当前RoutineContext绑定的具体协程实现,负责定义协程的执行逻辑。其余寄存器的值(如rbx、r12~r15等)在初始化时被置为0,以避免未定义行为。CRoutineEntry作为一个函数指针,会被设置为指向一个具体的执行函数(通常是协程的入口函数),而RoutineContext的sp变量则被设置为当前栈空间的栈底地址,即存放rbp寄存器值的内存地址。这一栈底地址的选择考虑了x86_64架构下栈的向下增长特性,确保后续压栈操作不会覆盖关键数据。
7.2.2 协程主体
协程的主体由CRoutine模块构成,其设计目标是为协程提供一个清晰的逻辑封装,包括状态管理、上下文绑定和执行控制。CRoutine的类成员变量如表所示,类成员函数如表所示。
CRoutine类成员变量
| 名称 | 用途 |
|---|---|
| Name | 协程的名字 |
| State | 协程的状态 |
| Context | 协程绑定的RoutineContext |
| Priority | 协程的优先级 |
| Main_stack | 主栈指针 |
| Current_routine | 当前线程执行的协程对应的CRoutine对象 |
| Func | 协程的执行体函数 |
CRoutine对外接口函数
| 名称 | 用途 |
|---|---|
| Run() | 执行Func函数 |
| Stop() | 设置协程的状态为STOP |
| Wake() | 设置协程的状态为READY |
| HangUp() | 设置协程的状态为IO_WAIT |
| Sleep() | 设置协程的状态为睡眠,暂停执行一段时间 |
| Yield() | 挂起当前协程 |
| Resume() | 恢复执行当前协程 |
| GetMainStack() | 获取主栈地址 |
| GetCurrentRoutine() | 获取Current_routine的值 |
CRoutine支持五种状态的相互切换,包括READY(就绪)、RUNNING(运行)、IO_WAIT(I/O等待)、SLEEP(睡眠)和STOP(停止),其状态转换过程如图所示。
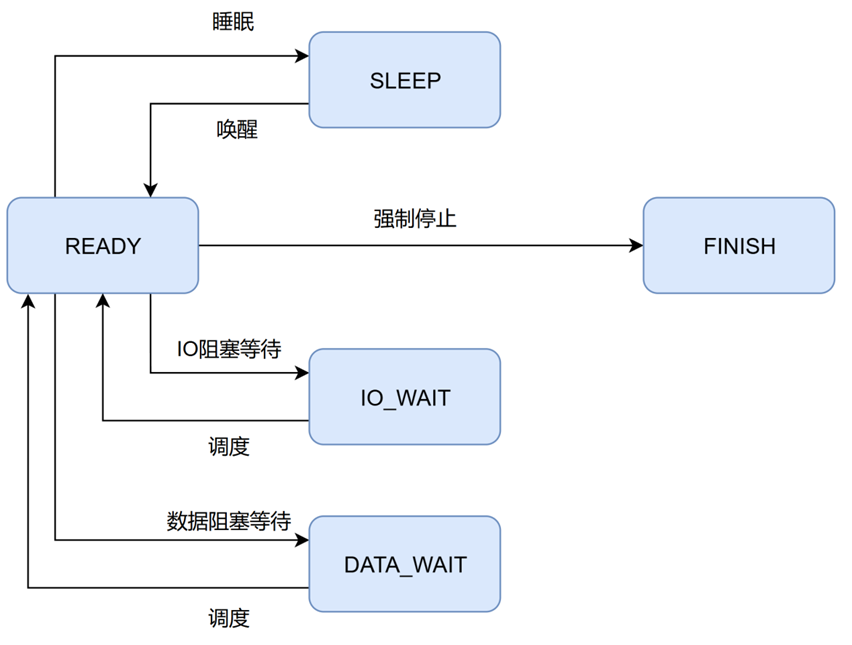
在初始化时,CRoutine被设置为READY状态,表示协程已准备好被调度器分配资源执行。状态的切换通过定义的成员函数实现,Sleep()可用于暂停协程以等待定时事件,而HangUp()则适用于异步I/O操作([52])的等待场景。在构造CRoutine时,会同步创建一个对应的RoutineContext,并通过Context成员变量建立关联。RoutineContext中的CRoutineEntry函数负责调用当前CRoutine的Run()函数以执行协程逻辑,执行完毕后则调用Yield()函数挂起当前协程,从而将控制权交回调度器。
7.2.3 协程执行
协程的执行由主线程中的协程调度器负责分配。在一个主线程中,可能同时存在多个协程,每个协程都可以被调度器动态切换执行。协程在运行时占用主线程的CPU时间片资源,与传统的多线程并发不同,协程通过协作式调度避免了线程间的竞争开销。调度器通过调用协程的Resume()函数恢复协程的执行,该函数内部实现换栈操作,即先保存主线程的栈状态,再恢复目标协程的栈状态。执行Resume()函数前,主线程栈和协程栈的状态如图1所示;执行后,栈状态如图2所示。
\1. 协程执行前栈空间
- 协程执行后栈空间
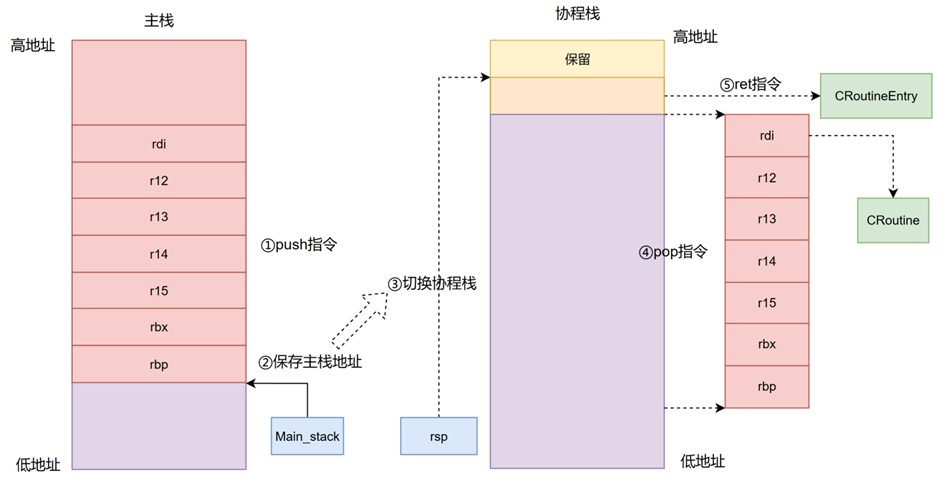
Resume()函数总共做了五个步骤:
- Step1保存主线程上下文,执行push指令,将rdi、r12~r15、rbx、rbp保存到主线程的栈空间中。随着压栈操作的进行,主线程的栈指针也会发生相应变化。
- Step2保存主栈指针,将主栈的栈指针保存到即将切换的协程的Main_stack成员变量中。协程执行完毕后,将根据Main_stack的值恢复主线程的上下文。
- Step3切换协程栈,协程的栈指针保存在RoutineContext的sp变量中,通过将rsp寄存器的值设置为sp变量的值,即完成了协程栈的切换。
- Step4恢复协程上下文,执行pop指令,将保存在协程栈中的rdi、r12~r15、rbx、rbp恢复到CPU的寄存器中,从而完成换栈操作。
- Step5跳转执行,执行ret指令,ret会从栈顶弹出一个值,并将该值加载到指令指针(RIP寄存器)中。此时,RIP会指向CRoutineEntry,而CRoutineEntry内部会调用协程的Run()函数,从而实现协程的执行。
7.2.4 协程挂起
上文提到,在CRoutineEntry函数中,协程完成Run()函数的执行后,需要调用Yield()函数主动将当前线程的CPU使用权交还给主线程继续执行。与线程的抢占式调度不同,协程的挂起是协作式的,由协程自身决定何时让出控制权。协程挂起的逻辑与运行逻辑相反:运行时是从主线程切换到协程,需要保存主线程上下文并恢复协程上下文;而挂起时则是保存当前协程的上下文并恢复主线程的上下文,其过程如图3所示。
\3. 协程挂起栈空间
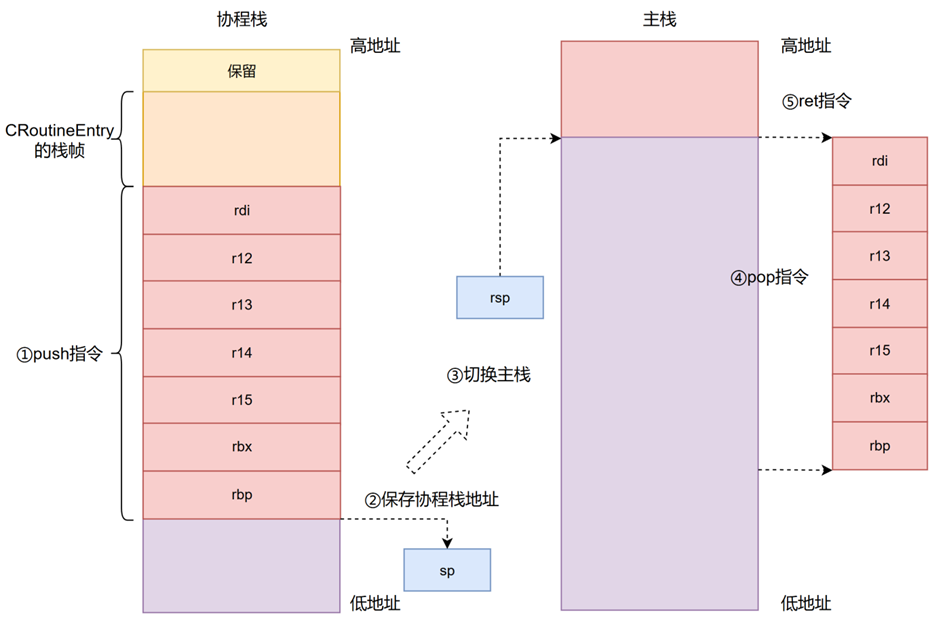
Yield()函数同样涉及到五个步骤的操作:
- Step1保存协程上下文,执行push指令,将当前协程的上下文(即rdi、r12~r15、rbx、rbp)保存到协程栈中,此时会发生压栈操作。
- Step2保存协程栈地址,将当前的rsp指针所指向的协程栈地址保存到RoutineContext的sp变量中。
- Step3切换主栈,在Resume()函数中,主栈的栈指针已被保存到Main_stack变量中,因此将rsp的值设置为Main_stack的值,即完成了从协程栈到主栈的切换。
- Step4恢复主线程上下文,执行pop指令,将Resume()函数中保存在主栈中的rdi、r12~r15、rbx、rbp寄存器的值恢复到CPU寄存器中。
- Step5返回主线程,执行ret指令,恢复主线程的执行流程。
7.3 协程调度器的设计
基于协程的程序运行逻辑如图4所示,在一个进程(Process)内运行着多个线程(Thread),每个线程内部运行着多个协程(CRoutine)。这些协程通过主进程的协程调度器(Scheduler)进行管理和调度,每个协程绑定独立的RoutineContext以保存其栈和上下文信息。调度器的设计目标是实现协程的高效分配和执行,确保任务的实时性和资源利用率。
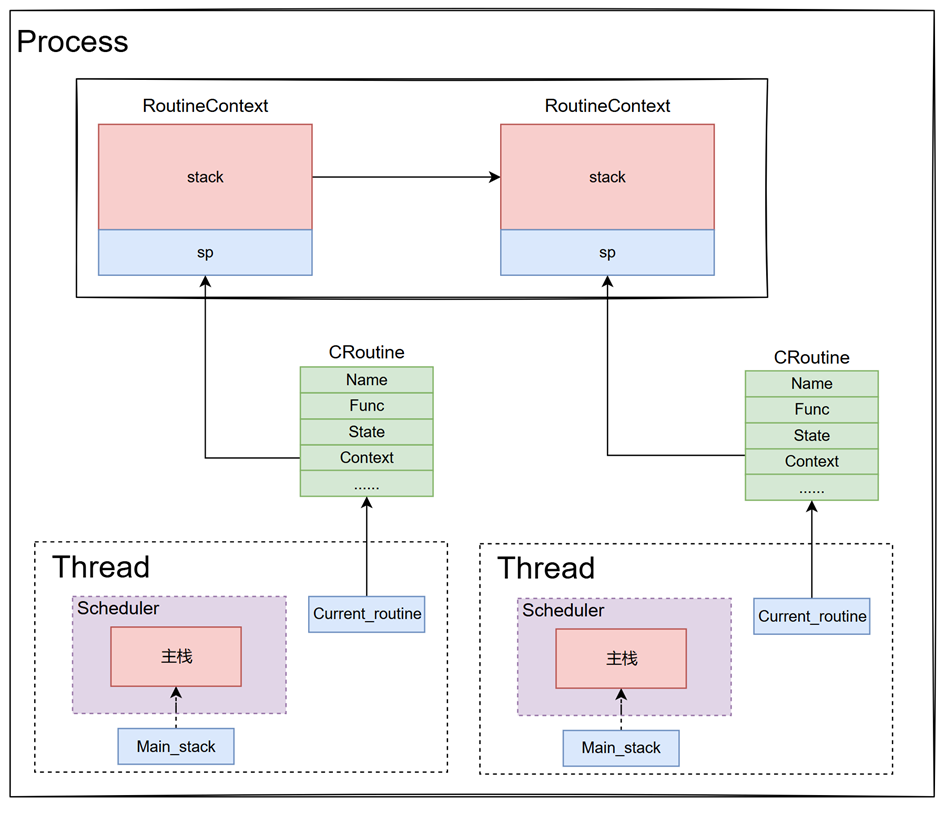
代码涉及到几个重要的类:
sheduler:调度器基类processor:抽象的cpu基类processor_context:抽象cpu的上下文
具体实现的子类:
SchedulerClassic、SchedulerChoreography:sheduler的子类,代表两种不同的调度器,目前只实现了SchedulerClassic这种调度器ClassicContext、ChoreographyContext:processor_context的子类,代表两种调度器对应的抽象cpu的上下文
这些类的关系如图所示:
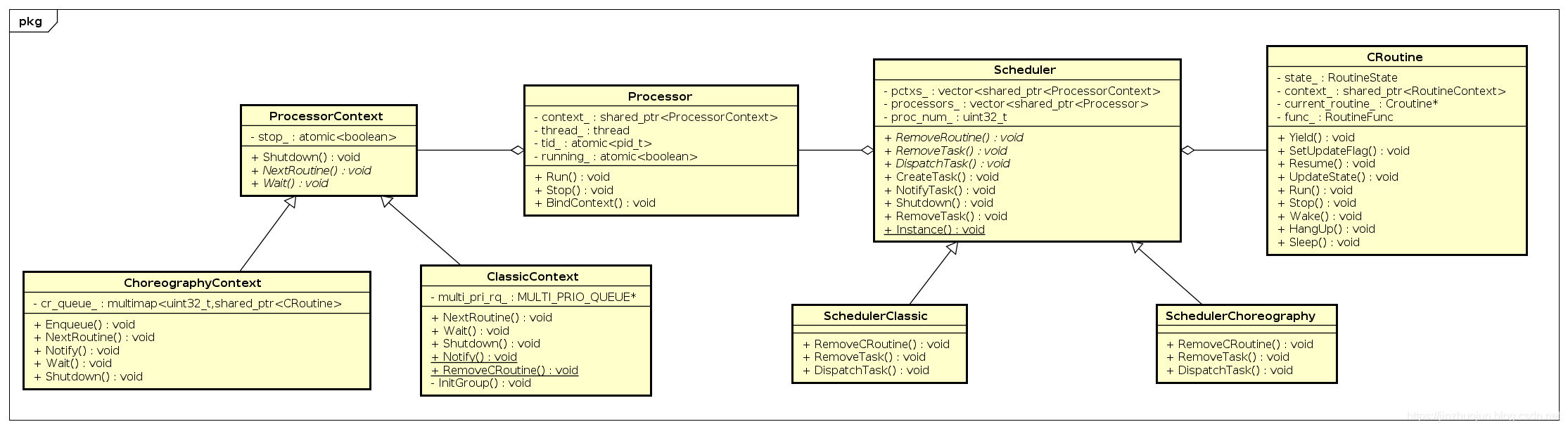
7.3.1 调度器配置
协程调度器支持通过配置文件灵活调整其运行特性,以适应不同的应用需求。一份典型的调度器配置文件采用JSON格式,便于解析和修改。其中,policy字段用于指定调度器的调度策略,本文目前实现了一种名为classic的调度策略;classic_conf字段则用于定义classic策略下的具体配置细节,例如线程分组和协程优先级。

在classic策略下,调度器会对进程中的线程和协程进行分组管理,同一组内的线程和协程共享相同的调度方式和资源分配策略。组(groups)支持的配置选项如表所示,涵盖了线程数量、CPU亲和性、调度策略和任务优先级等关键参数。配置文件中的tasks字段用于定义当前组下运行的协程,用户可以通过该字段设置协程的名称和优先级。例如,在机器人系统中,可将环境感知任务配置为高优先级协程,而日志记录任务配置为低优先级协程,以确保关键任务的实时性。
| 配置选项 | 用途 |
|---|---|
| name | 组的名字 |
| processor_num | 线程数量 |
| affinity | 线程的cpu亲和性 |
| cpuset | 线程运行的cpu核心号 |
| processor_policy | 线程调度策略 |
| processor_prio | 线程优先级 |
| tasks.name | 协程的名字 |
| tasks.prio | 协程的优先级 |
7.3.2 调度器管理
调度器(Scheduler)的主要成员函数如表所示,涵盖了任务创建、派发和线程管理的核心功能。
| 成员函数 | 用途 |
|---|---|
| CreateTask() | 创建协程任务 |
| DispatchTask() | 派发协程任务到线程上 |
| CreateProcessor() | 创建线程,并设置cpu亲和性和调度策略 |
| NotifyProcessor() | 唤醒线程 |
在Scheduler的构造函数中,首先会解析配置文件并读取相关配置信息,然后调用CreateProcessor()函数。该函数会根据配置文件中的processor_num参数创建相应数量的线程,并依次设置线程的CPU亲和性策略和调度策略。
线程的CPU 亲和性策略可通过POSIX线程库中的 pthread_setaffinity_np函数实现,CPU 亲和性策略包括以下两种模式:
- “1to1”模式:每个线程在运行过程中始终绑定到一个固定的 CPU 核心。例如,在group2中,CPU亲和性策略设为“1to1”,线程数量为16个,核心号范围为“8-15,24-31”。在此模式下,1号线程仅能运行在8号CPU上,2号线程仅能运行在9号CPU上,依此类推。
- “range”模式:线程可以在指定的 CPU 核心范围内自由调度。例如,在 group1 中,设置的可运行CPU核心号为“0-7,16-23”,线程数量为16个。在此模式下,这16个线程可在CPU -7和16-23之间灵活运行。
线程的调度策略决定了线程在系统中的运行方式,影响其优先级和执行顺序。POSIX线程库提供pthread_setschedparam函数,用于设置线程的调度策略和优先级。常见的调度策略包括:
- 1.SCHED_FIFO([57])(先进先出调度):该策略适用于实时任务,线程按照优先级执行,高优先级线程不会被低优先级线程抢占,直到线程主动释放CPU或被阻塞。
- 2.SCHED_RR([58])(时间片轮转调度):该策略与 SCHED_FIFO 类似,但线程会在相同优先级下轮流执行,每个线程拥有固定的时间片,时间片到期后,调度器会将其放到同优先级的队列末尾。
- 3.SCHED_OTHER([59])(普通时间共享调度):这是默认的调度策略,适用于大多数普通任务。线程的优先级较低,并且调度器会根据系统负载动态调整线程的执行顺序,以保证公平性。
Scheduler创建的所有线程会共同访问一个全局的数据结构:CR_GROUP,CR_GROUP是一个映射表,以配置文件中的group的name作为键,MULTI_PRIO_QUEUE作为值,MULTI_PRIO_QUEUE为一个数组,此数组按照协程的优先级进行排列,数组中的每一个元素即为此优先级对应的协程队列。
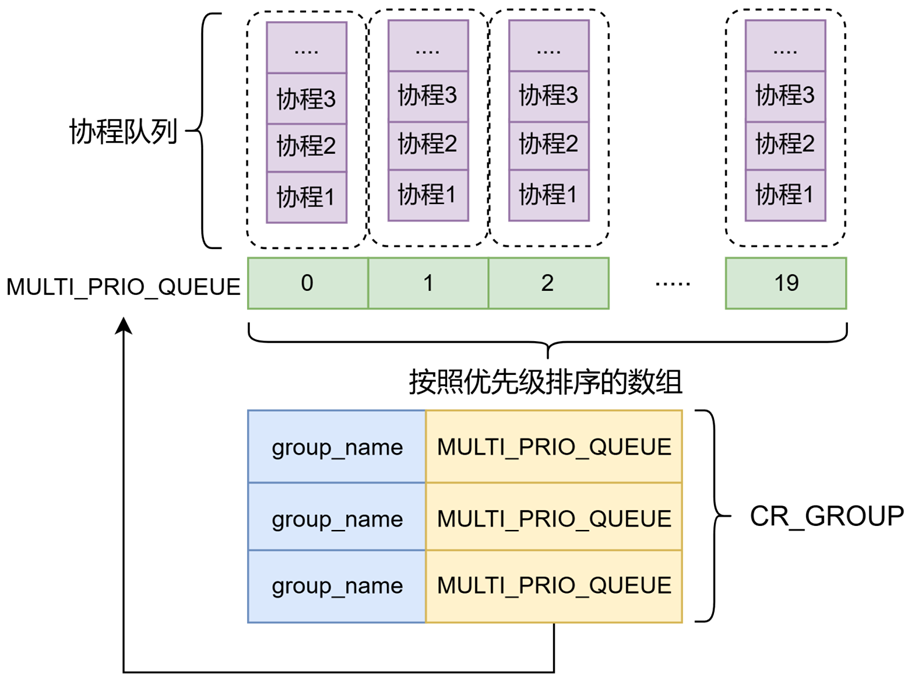
在完成线程的创建后,全局的线程布置结构如图所示,每个线程主体为Run()函数,此函数的逻辑为:(1)根据当前线程所属的group的名字作为键去访问CR_GROUP中对应的协程优先级数组。(2)通过双重循环遍历,检查所有队列中是否有状态为READY的协程。若找到,则返回该协程并调用Resume()执行;若无就绪协程,则阻塞线程等待NotifyProcessor()唤醒。
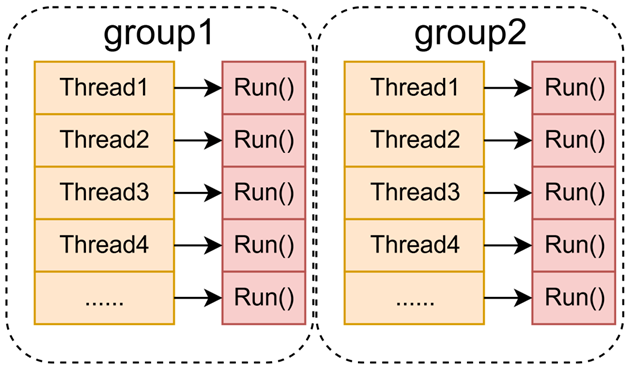
协程任务的创建是通过CreateTask()函数来实现的,在此函数中会创建一个新的协程(CRoutine),并根据协程的名字分配优先级,最后将其放入CR_GROUP的协程队列中。
7.4 基于协程的通信架构设计
7.4.1 Cache_buffer
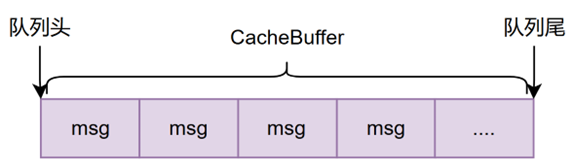
为实现协程任务处理与分布式通信中间件的协同运行,设计了一套数据缓存与分发机制。核心组件Cache_buffer用于存储从Receiver读取的数据,其结构为环形队列,队列中的每个元素对应一条消息数据,具体设计如图所示。基于Cache_buffer,进一步构造了ChannelBuffer,采用<channel_id, Cache_buffer>键值对形式,使每个channel具备独立的数据缓存能力。
7.4.2 ChannelBuffer
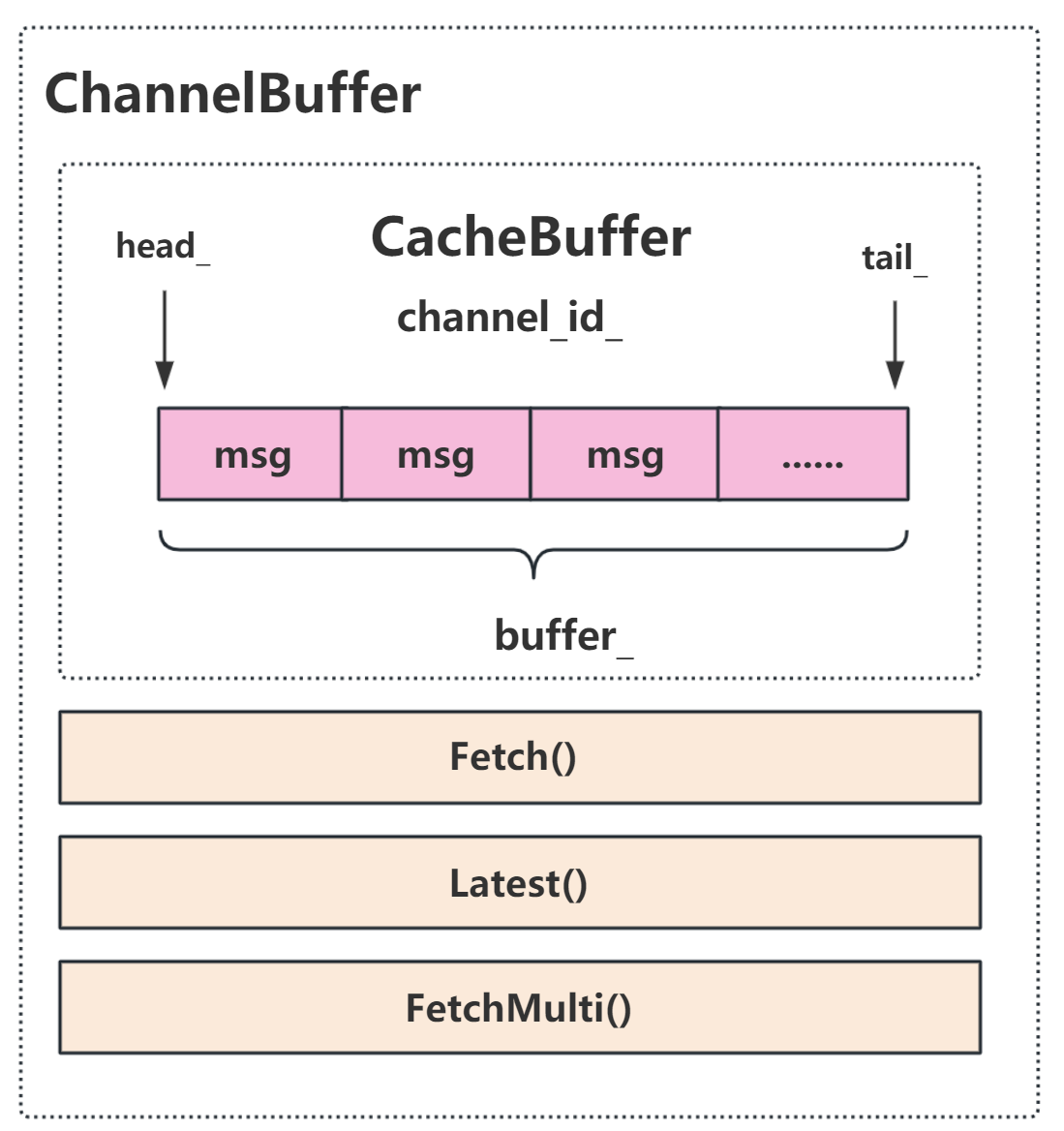
ChannelBuffer是对CacheBuffer的包装,提供了三个函数用于操控内部包含的这个ChannelBuffer,Fetch用于取出指定index位置的数据,Latest用于获取CacheBuffer最新添加的数据,FetchMulti用于获取指定个数的一堆数据。- 每个
ChannelBuffer都会和一个确定的channel_id_对应,即一个channel_id_和一个Cache_buffer组成一队
7.4.3 DataNotifier
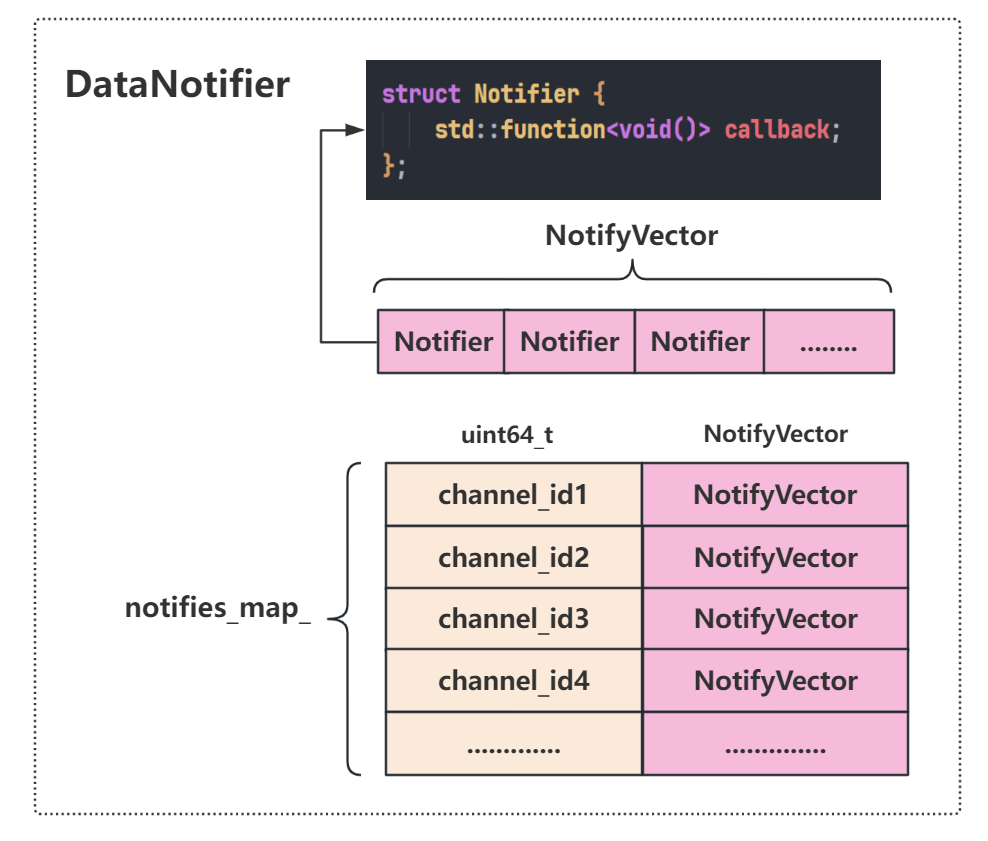
DataNotifier内部维护了一个map,map的索引为channel_id,值为一个vector,这个vector内部会保存很多个Notifier,Notifier实际上就是一个函数DataNotifier提供了一个AddNotifier函数来向对应channel_id的NotifyVector添加NotifierDataNotifier提供了一个Notify函数,函数参数为channel_id,此函数会把对应的NotifyVector中保存的Notifier函数遍历执行一遍
7.4.4 协程通信流程
在CyberRT的设计中,订阅方被封装为节点(Node)中的Subscriber。每个Subscriber创建时生成一个协程(CRoutine),用于处理来自Publisher的数据,其通信架构如图所示。同时,每个Subscriber创建时同步生成一个协程,并绑定一个DataVistor对象。DataVistor内部维护一个ChannelBuffer,协程通过回调函数持续尝试从中提取数据。若ChannelBuffer为空,协程调用Yield()函数切换至等待状态;若提取到数据,则执行Subscriber的回调逻辑,处理完成后再次调用Yield()切换。
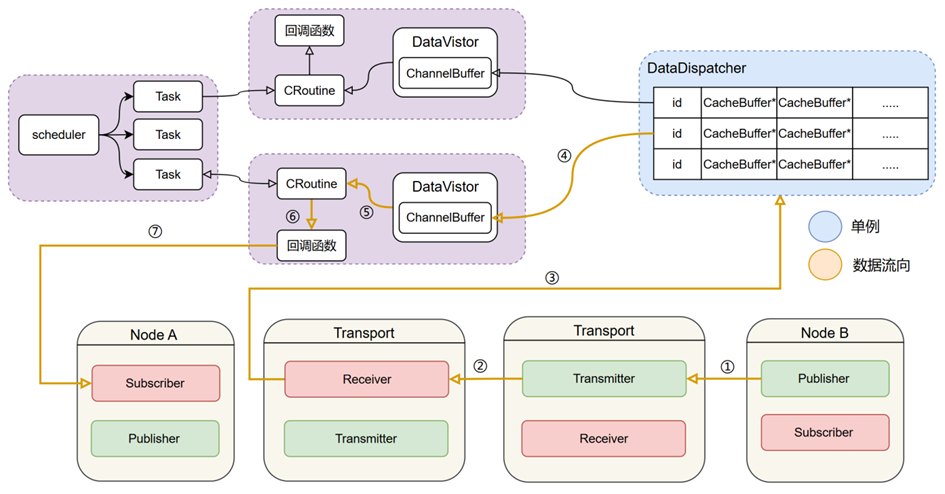
数据分发由DataDispatcher负责,其设计为全局单例对象。当DataVistor创建时,会根据对应的channel将其ChannelBuffer的读写权限注册至DataDispatcher。Transport层的Receiver接收到某channel的数据后,DataDispatcher将数据填充至该channel对应的ChannelBuffer,供协程后续处理。这种机制通过集中式分发与权限注册,实现了数据从接收到处理的有序传递。
 微信
微信 支付宝
支付宝
![ARM64-Trust-Firmware[3]-BL1解析](/2026/01/24/ARM64-Trust-Firmware-3-BL1%E8%A7%A3%E6%9E%90/17692290470595.png)
![ARM64-Trust-Firmware[2]-启动ATF](/2026/01/24/ARM64-Trust-Firmware-2-%E5%90%AF%E5%8A%A8ATF/17692287555201.png)
![ARM64-Trust-Firmware[1]-ARM安全架构](/2026/01/24/ARM64-Trust-Firmware-1-ARM%E5%AE%89%E5%85%A8%E6%9E%B6%E6%9E%84/17692284856153.png)
![Xhyper剖析[6]--中断虚拟化](/2026/01/20/Xhyper%E5%89%96%E6%9E%90-6-%E4%B8%AD%E6%96%AD%E8%99%9A%E6%8B%9F%E5%8C%96/17689244713913.png)
![Xhyper剖析[5]--MMIO虚拟化](/2026/01/20/Xhyper%E5%89%96%E6%9E%90-5-MMIO%E8%99%9A%E6%8B%9F%E5%8C%96/17689243819381.png)