协作式多任务调度
1. 代码的一些修改
1.1 trap的bug修改
在上一节实现U模式的trap机制时,我在trap_handler函数中,在函数最后通过__restore(cx)来切换回用户态,这里实际是不用的,我就说为啥我在用户程序里为啥不加一个while循环卡在那儿就会报奇怪的错误。
原因在于当程序从trap_handler 返回之后会从调用 trap_handler 的下一条指令开始执行:
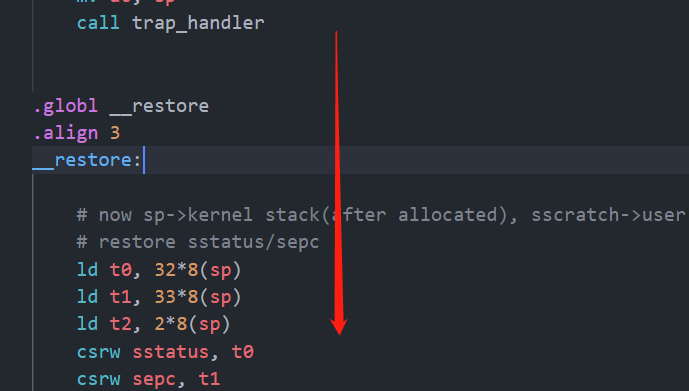
call trap_handler 实际的汇编会被转换一条jal的跳转指令:

jal ra,1876会做两个操作,一是将当前PC+8存到ra寄存器中,然后跳转到和当前地址相差1876的地方执行即0x802007ba,而0x802007ba就是trap_handler函数的地址,各个函数的地址可以在生成的os.map中找到。因此在执行完毕trap_handler函数后就会跳转到call trap_handler 的下一条指令,这下一条指令就是_restore的第一条指令,编译器在编译时是这样编译的。所以直接将trap_handler函数的__restore(cx)干掉。
1.2 实现sys_write
我再os目录下新建了一个app.c,上一节的batch.c在本章内容中可以干掉,在app.c中首先了实现了用户态的sys_write函数:
|
write的系统调用号是64定义在os.h中,然后需要修改内核的trap_handler函数,对系统调用号进行分发:
TrapContext* trap_handler(TrapContext* cx) |
__SYSCALL函数定义在syscall.c中,需要新建syscall.c,可以看见其实调用内核的printf函数去输出
/* syscall.c */ |
由于sys_wirte的其中一个参数是字符串的长度,需要调用strlen去计算,如果我们调用编译器的标准库会产生重定义错误,因此我们自己来实现一个,新建一个string.c,实现了两个辅助函数如下:
/* string.c */ |
ok,现在就可以在用户态的程序调用sys_write来实现串口输出数据了。
2. 协作式多任务
2.1 任务的切换
在上一节中我们可以编写一个应用程序让它运行下去,运行完毕后可以让CPU接着运行下一个程序,这叫做批处理系统,cpu可以按照顺序依次运行用户程序。什么是协作式多任务呢就是如果一个用户程序在做一些等待的事情的时候比如等待外设响应而不需要占用cpu计算资源的时候可以让出cpu的使用权让下一个用户程序执行,当外设响应完毕后重新拿到cpu使用权继续执行,这大大的提高了cpu的执行效率。从一个程序的任务切换到另外一个程序的任务称为 任务切换 。为了确保切换后的任务能够正确继续执行,操作系统需要支持让任务的执行“暂停”和“继续”。
和trap一样从用户态切换到内核态时需要保存用户态的执行状态,同样从一个任务切换到另一个任务也需要保存当前任务的执行状态,该任务重新拿到cpu使用权后能够恢复执行状态继续执行。
实现协作式多任务的关键在于任务主动放弃cpu执行权,用户态的程序会去调用一个sys_yield的系统调用来告诉操作系统我要放弃cpu使用权了,然后操作系统就可以进行任务切换了,所以任务的切换是发生在S态的,任务在操作系统切换完毕后,同样通过_restore回到用户态执行程序,不过此时已经进行了任务切换,所以_restore回到的是切换后的任务。
所以,任务切换其实是来自两个不同应用在内核中的 Trap 控制流之间的切换。当一个应用 Trap 到 S 模式的操作系统内核中进行进一步处理的时候,我们可以设计一个函数来给Trap 控制流调用,从而进行任务切换。这个函数我们定义为__switch
这个函数表面上就是一个普通的函数调用:在 __switch 返回之后,将继续从调用该函数的位置继续向下执行。但是其间却隐藏着复杂的控制流切换过程。具体来说,调用 __switch 之后直到它返回前的这段时间,原 Trap 控制流 A 会先被暂停并被切换出去, CPU 转而运行另一个应用在内核中的 Trap 控制流 B 。然后在某个合适的时机,原 Trap 控制流 A 才会从某一条 Trap 控制流 C (很有可能不是它之前切换到的 B )切换回来继续执行并最终返回。
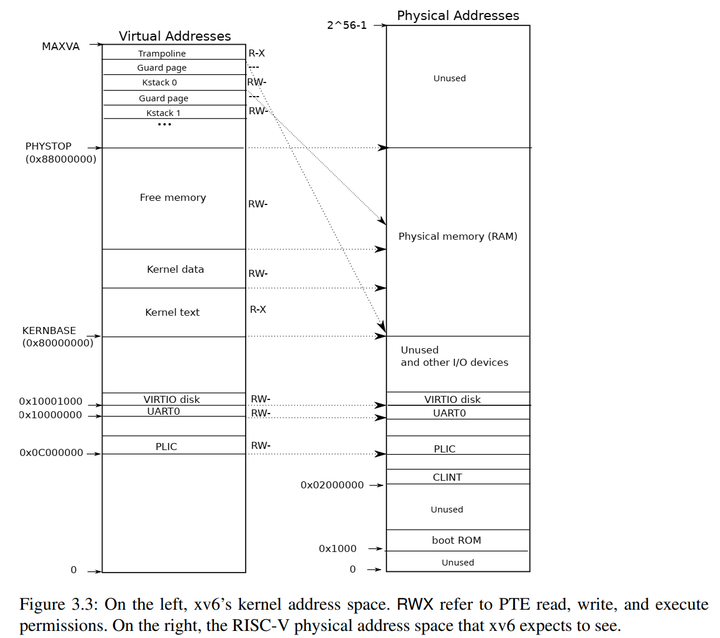
同样在内核进行切换时我们需要保存任务在内核执行trap时的执行状态,任务从用户态通过trap进入内核态后,内核栈上首先保存了用户态的trap上下文,然后会保存内核在对Trap处理过程中留下的调用栈信息,如下图所示:
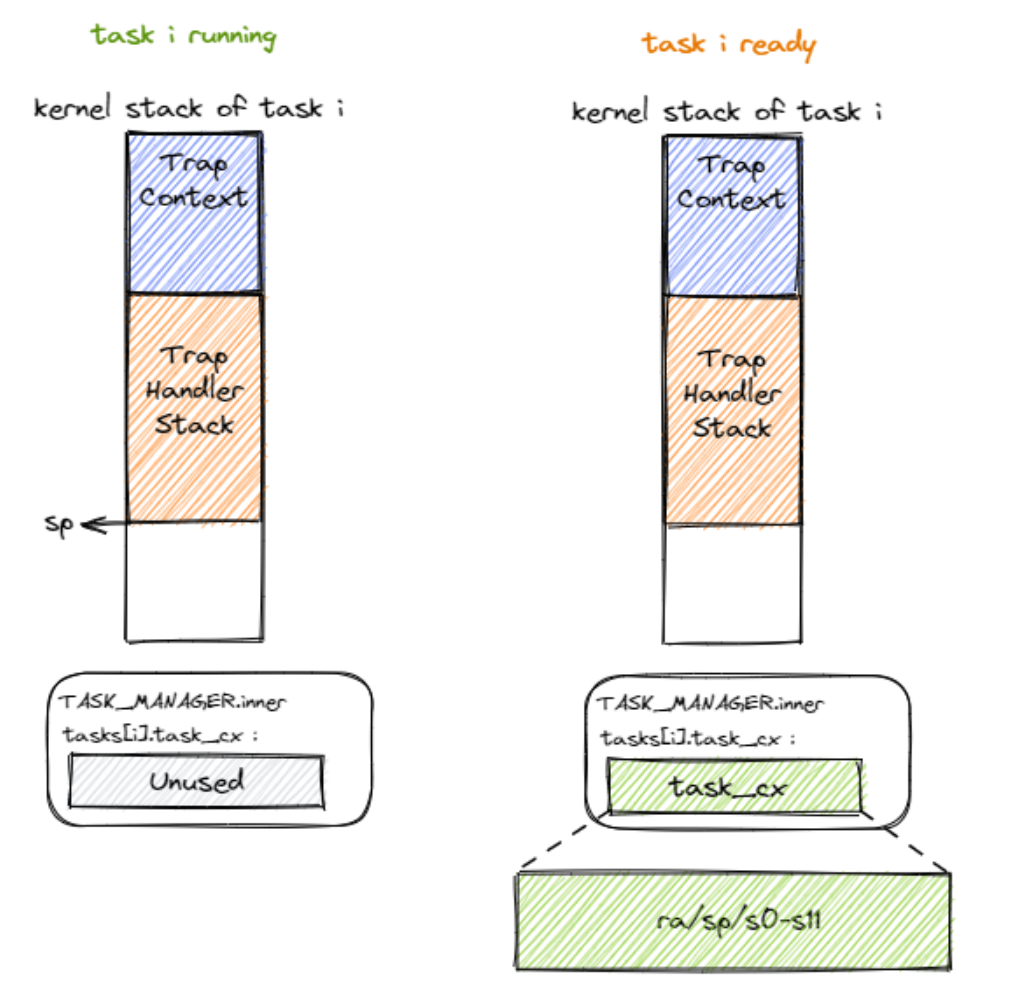
任务在切换后还需要回来继续执行,因此需要在执行__switch 函数时保存当前任务的CPU寄存器的信息,这里我们称为任务上下文(Task Context)。每个任务都有自己的任务上下文,每个任务也有自己的内核栈和用户栈空间,所以我们首先需要为每个任务定义内核栈和用户栈。新建一个task.c文件:
|
接下来我们来定义TaskContext,在context.h新增如下代码:
/* S模式的任务上下文 */ |
可以看见需要保存的寄存器包括ra寄存器,sp寄存器,s0~s11寄存器,,因为从本质上来讲__switch属于一个函数调用,我们需要遵守riscv的函数调用规范:
| 寄存器组 | 保存者 | 功能 |
|---|---|---|
| a0 |
调用者保存 | 用来传递输入参数。其中的 a0 和 a1 还用来保存返回值。 |
| t0 |
调用者保存 | 作为临时寄存器使用,在被调函数中可以随意使用无需保存。 |
| s0 |
被调用者保存 | 作为临时寄存器使用,被调函数保存后才能在被调函数中使用。 |
ra 很重要,它记录了 __switch 函数返回之后应该跳转到哪里继续执行,从而在任务切换完成并 ret 之后能到正确的位置。对于一般的函数而言,Rust/C 编译器会在函数的起始位置自动生成代码来保存 s0~s11 这些被调用者保存的寄存器。但 __switch 是一个用汇编代码写的特殊函数,它不会被 Rust/C 编译器处理,所以我们需要在 __switch 中手动编写保存 s0~s11 的汇编代码。 不用保存其它寄存器是因为:其它寄存器中,属于调用者保存的寄存器是由编译器在高级语言编写的调用函数中自动生成的代码来完成保存的;还有一些寄存器属于临时寄存器,不需要保存和恢复。
所以在调用__switch函数进行任务切换时,我们需要将当前任务的这些寄存器保存,然后将下一个要切换的任务的寄存器从拿出来然后完成寄存器替换。
因此每个任务都有一个保存自己任务上下文的地方,这个地方我们定义为TaskControlBlock,在TaskControlBlock不止可以保存任务的上下文信息,还可以保存任务的运行状态,在新建一个task.h:
|
在task.h文件中我定义了一个TaskControlBlock来保存任务的信息,一个任务的信息包括这个任务的状态和任务上下文的信息,然后在task.c中定义一个数组,由此每个任务都有保存自己任务上下文的地方了。任务的状态有4钟:未初始化、准备执行、正在执行、已退出。
struct TaskControlBlock tasks[MAX_TASKS]; |
对于当前正在执行的任务的 Trap 控制流,我们用一个名为 current_task_cx_ptr 的变量来保存放置当前任务上下文的地址;而用next_task_cx_ptr的变量来保存放置下一个要执行任务的上下文的地址。利用 C 语言的引用来描述的话就是:
TaskContext *current_task_cx_ptr = &tasks[current].task_cx; |
接下来我们从栈上内容的角度来看__switch的整体流程:
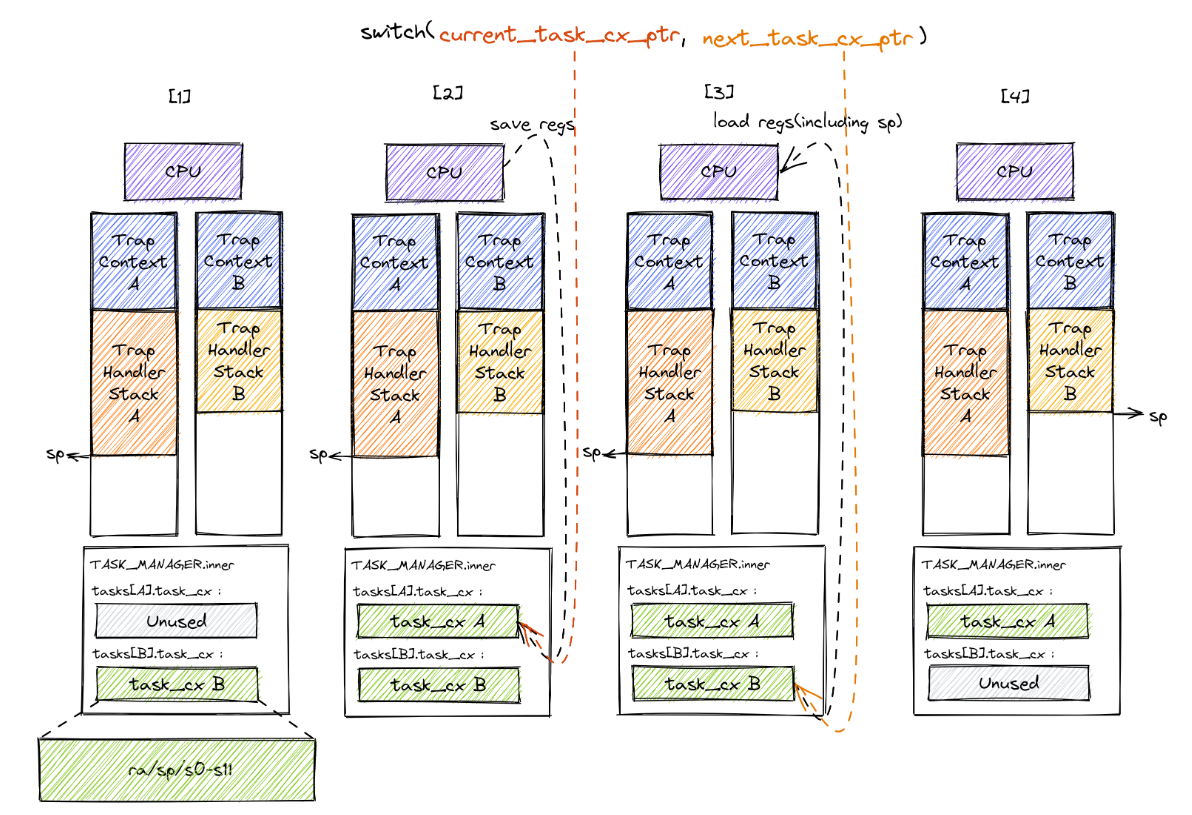
Trap 控制流在调用 __switch 之前就需要明确知道即将切换到哪一条目前正处于暂停状态的 Trap 控制流,因此 __switch 有两个参数,第一个参数代表它自己,第二个参数则代表即将切换到的那条 Trap 控制流。这里我们用上面提到过的 current_task_cx_ptr 和 next_task_cx_ptr 作为代表。在上图中我们假设某次 __switch 调用要从 Trap 控制流 A 切换到 B,一共可以分为四个阶段,在每个阶段中我们都给出了 A 和 B 内核栈上的内容。
- 阶段 [1]:在 Trap 控制流 A 调用
__switch之前,A 的内核栈上只有 Trap 上下文和 Trap 处理函数的调用栈信息,而 B 是之前被切换出去的; - 阶段 [2]:A 在 A 任务上下文空间在里面保存 CPU 当前的寄存器快照;
- 阶段 [3]:这一步极为关键,读取
next_task_cx_ptr指向的 B 任务上下文,根据 B 任务上下文保存的内容来恢复ra寄存器、s0~s11寄存器以及sp寄存器。只有这一步做完后,__switch才能做到一个函数跨两条控制流执行,即 通过换栈也就实现了控制流的切换 。 - 阶段 [4]:上一步寄存器恢复完成后,可以看到通过恢复
sp寄存器换到了任务 B 的内核栈上,进而实现了控制流的切换。这就是为什么__switch能做到一个函数跨两条控制流执行。此后,当 CPU 执行ret汇编伪指令完成__switch函数返回后,任务 B 可以从调用__switch的位置继续向下执行。
从结果来看,我们看到 A 控制流 和 B 控制流的状态发生了互换, A 在保存任务上下文之后进入暂停状态,而 B 则恢复了上下文并在 CPU 上继续执行。
所以__switch的实现代码如下,新建一个switch.S文件:
.altmacro |
综上所述,__switch进行了一个换栈的操作,在内核态悄悄地把寄存器地执行状态全部修改了,再次回到用户态执行时,执行的就是另外一个用户程序了。
2.2 协作式调度
首先在app.c中封装一下sys_yield()函数:
size_t sys_yield() |
然后修改一下内核的__SYSCALL分发函数:
void __SYSCALL(size_t syscall_id, reg_t arg1, reg_t arg2, reg_t arg3) { |
__NR_sched_yield定义在os.h中:#define __NR_sched_yield 124
可以看见当用户态程序调用sys_yield()来手动放弃cpu使用权时,内核会去调用一个schedule();的函数来完成任务切换,这个函数我是定义在task.c中的
来看一下task.c中做了哪些修改:
- 首先定义了两个变量,一个用来表示当前的执行的任务号,一个用来表示用户常见的任务数量。
static int _current = 0; |
- 然后定义了一个
task_create(void (*task_entry)(void))函数来创建任务,此函数传入的参数为一个函数指针,即用户态的应用程序的地址。在创建任务时我们首先需要为每个任务先构造该任务的trap上下文,包括入口地址和用户栈指针,并将其压入到内核栈顶,然后设置sepc、sstatus、sp寄存器的值。这一步和上一章一样,下一步就是需要为每一个任务构造一个初始的内核的任务上下文,这里会调用一个tcx_init的函数,在这个函数里面我们会初始化任务的任务上下文。再完成trap上下文和任务上下文的构造后会将_top的值加一代表多了一个任务
void task_create(void (*task_entry)(void)) |
- 然后定义了一个
tcx_init的函数用来初始化创建的任务的任务上下文信息,传入的参数为任务的内核栈地址,这里为啥把任务的ra寄存器的值设置为__restore,那是因为在应用真正跑起来之前,需要 CPU 第一次从内核态进入用户态。我们在上一篇文章中也介绍过实现方法,只需在内核栈上压入构造好的 Trap 上下文,然后__restore即可。但是现在我们是通过__switch来进行任务切换的,而__switch切换完成后会返回到ra的地方执行,我们这里第一次将ra设置为__restore,那么程序就可以从内核态切换回用户态执行了,为此我们需要定义一个run_first_task()的函数来完成第一次切换。可以看见在run_first_task()函数中,先构造了一个_unused的任务上下文,然后调用__switch函数让切换到tasks[0]进行执行,用于初始化时tasks[0]的ra被设置成了__restore的地址,所以就能去返回用户态运行task0了。需要注意的是,__restore的实现需要做出变化:它 不再需要 在开头mv sp, a0了。因为在__switch之后,sp就已经正确指向了我们需要的Trap上下文地址。
这里我有个疑惑,要是正常的
trap执行流,从trap_handler返回后去执行__restore函数,此时难道不应该需要``mv sp, a0吗,还是说在trap_handler函数中并没有修改栈指针,从代码逻辑上来看确实不会修改栈指针的值,即使由于一些计算操作需要压栈存储局部变量的值,但是trap_handler执行完毕后,sp`会移动到原本的位置。
struct TaskContext tcx_init(reg_t kstack_ptr) { |
- 最后我们来看
schedule()函数,首先判断一下创建的任务数量不为0,然后进行轮转调度,如果下一个任务的状态是ready,那么就切换到下一个任务执行,并且将当前任务的状态置为ready,这里其实应该用for循环的,但是用于我在task_create默认任务的状态为ready,所以这里就无所谓了。
void schedule() |
2.3 测试
首先在app.c中新建三个应用程序:
void task1() |
这里的task_delay函数如下:
/* |
然后调用task_create来创建任务:
void task_init(void) |
最后修改main函数来执行:
|
编译测试:
timer@DESKTOP-JI9EVEH:~/quard-star$ ./build.sh |

可以看见三个任务交替执行打印,没问题!
这里说一个比较难理解的点就是只有第一次执行应用程序A的时候的ra是__restore,当A任务执行完毕__switch后,它的ra就变成了__switch的下一条地址,就是schedule()函数执行完毕了。第二次B任务调用__switch切换回A的时候,此时就会返回到__switch的下一条地址执行,我们是在__sys_yield()中调用schedule的,所以会依次完成函数调用返回,从schedule返回到__sys_yield,再返回到__SYSCALL,最后返回到trap_handler,而在本文开头提到过trap_handler执行完毕后会去执行__restore,所以这样A才能返回到用户空间程序继续执行。
参考链接
 微信
微信 支付宝
支付宝