
Linux内核中同步机制的底层实现
Linux内核同步机制剖析
在Linux内核中提供了四种处理并发和竞争的方法,分别是原子操作、自旋锁、信号量、互斥量,事先说明下我使用的linux内核为版本为4.19.232
1. 原子变量
在了解原子变量在linux内核中是如何实现之前,建议先了解以下SMP系统和UP系统的不同,然后学习以下cache一致性相关知识,这里给出一个参考链接
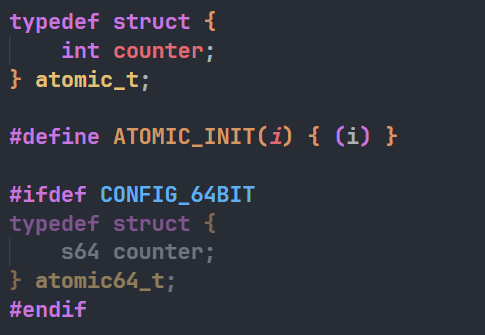
原子操作又可以进一步细分为“整型原子操作”和“位原子操作”,这里首先对整型原子操作进行讲解。在 Linux 内核中使用 atomic_t 和 atomic64_t 结构体分别来完成 32 位系统和 64 位系统的整形数据原子操作,两个结构体定义在内核源码/include/linux/types.h文件中,具体定义如下:
对整型原子变量的操作有以下一些函数,定义在内核源码的/include/linux/atomic.h中,
| 函数 | 描述 |
|---|---|
ATOMIC_INIT(int i) |
定义原子变量的时候对其初始化,赋值为 i |
int atomic_read(atomic_t *v) |
读取 v 的值,并且返回。 |
void atomic_set(atomic_t *v, int i) |
向原子变量 v 写入 i 值。 |
void atomic_add(int i, atomic_t *v) |
原子变量 v 加上 i 值。 |
void atomic_sub(int i, atomic_t *v) |
原子变量 v 减去 i 值。 |
void atomic_inc(atomic_t *v) |
原子变量 v 加 1 |
void atomic_dec(atomic_t *v) |
原子变量 v 减 1 |
int atomic_dec_return(atomic_t *v) |
原子变量 v 减 1,并返回 v 的值。 |
int atomic_inc_return(atomic_t *v) |
原子变量 v 加 1,并返回 v 的值。 |
int atomic_sub_and_test(int i, atomic_t *v) |
原子变量 v 减 i,如果结果为 0 就返回真,否则返回假 |
int atomic_dec_and_test(atomic_t *v) |
原子变量 v 减 1,如果结果为 0 就返回真,否则返回假 |
int atomic_inc_and_test(atomic_t *v) |
原子变量 v 加 1,如果结果为 0 就返回真,否则返回假 |
int atomic_add_negative(int i, atomic_t *v) |
原子变量 v 加 i,如果结果为负就返回真,否则返回假 |
对原子位操作的函数有如下,和原子整形变量不同,原子位操作没有 atomic_t 的数据结构,原子位操作是直接对内存进行操作
| 函数 | 描述 |
|---|---|
void set_bit(int nr, void *p) |
将 p 地址的第 nr 位置 1 |
void clear_bit(int nr,void *p) |
将 p 地址的第 nr 位清零 |
void change_bit(int nr, void *p) |
将 p 地址的第 nr 位进行翻转 |
int test_bit(int nr, void *p) |
获取 p 地址的第 nr 位的值 |
int test_and_set_bit(int nr, void *p) |
将 p 地址的第 nr 位置 1,并且返回 nr 位原来的值 |
int test_and_clear_bit(int nr, void *p) |
将 p 地址的第 nr 位清零,并且返回 nr 位原来的值 |
int test_and_change_bit(int nr, void *p) |
将 p 地址的第 nr 位翻转,并且返回 nr 位原来的值 |
我们以原子变量加操作的源码来分析,原子变量的操作在不同体系架构下是不同的,假设我现在定义一个原子变量,然后对其执行加操作:
|
atomic_inc这个宏定义在linux/atomic.h中:

可以看见atomic_inc实际上会去调用atomic_add来使得原子变量加一,atomic_add是一个和体系架构相关的宏函数,我们以x86平台和arm平台为例子,对于linux/atomic.h这个文件无论哪种架构都会去包含\#include <asm/atomic.h>这个头文件,不同的架构这个头文件内容是不一样的。
1.1 X86平台原子操作的底层实现
我们首先来分析x86架构,<asm/atomic.h>这个头文件位于arch/x86/include/asm/atomic.h,在这个文件的最底部包含了一个头文件:<asm-generic/atomic-instrumented.h>
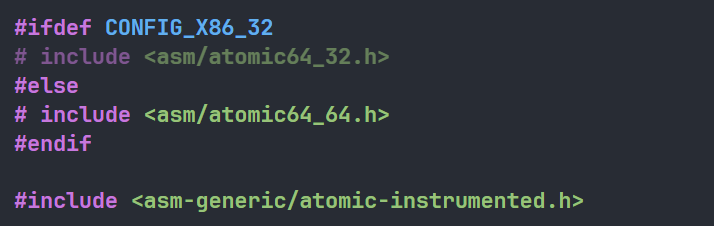
在<asm-generic/atomic-instrumented.h>中定义了和x86架构下原子变量操作的函数
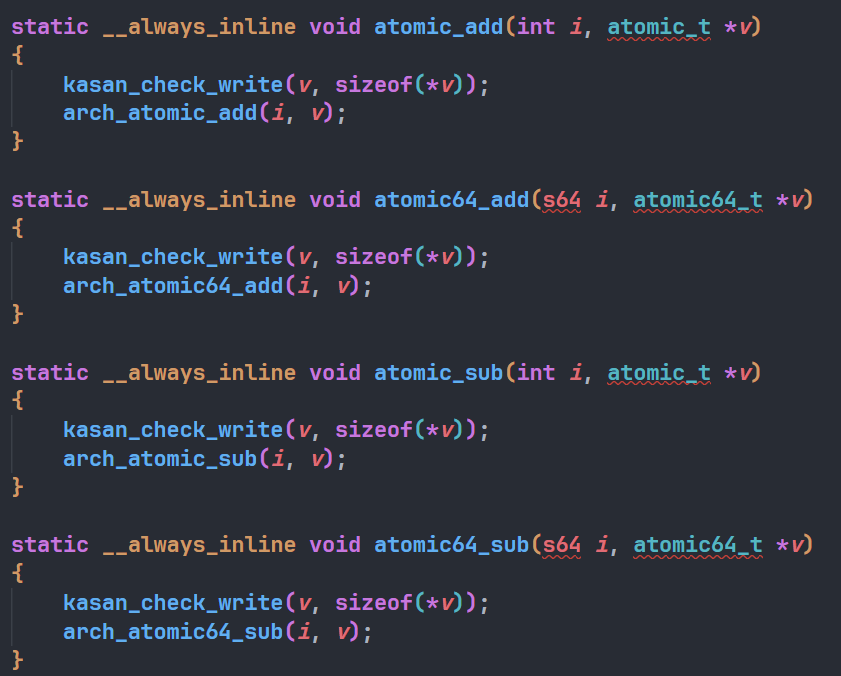
例如atomic_add会去调用arch_atomic_add,而arch_atomic_add就定义在arch/x86/include/asm/atomic.h中:
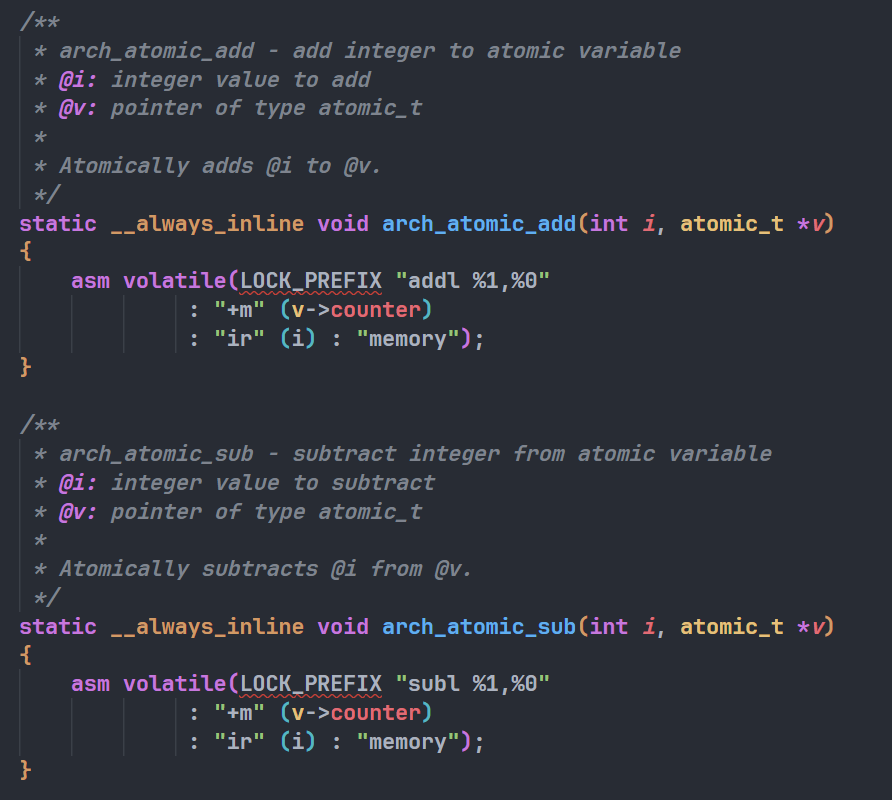
arch_atomic_add这个函数内部做的操作就是原子变量加一,它是如何做的呢,先来看LOCK_PREFIX这个宏,定义在arch/x86/include/asm/alternative-asm.h中:
|
可以看见只有在SMP系统下此宏才会被定义,在SMP系统下涉及到多核之间的cache数据同步与竞争关系,此时才会去定义这个宏,在不是SMP的系统下此宏为空,即单核情况下,这个宏为空,在单核情况下,上面的arch_atomic_add函数就变成了:
static __always_inline void arch_atomic_add(int i, atomic_t *v) |
addl指令用于执行32位整数加法操作,%1代表i这个参数,%0代表v->vounter这个参数,addl指令有三个步骤- 取值:汇编指令首先从
%1(即i)获取一个整数值。 - 加法运算:将从
%1取得的值加到%0(即v->counter内存位置的当前值)上。 - 存储结果:将加法的结果写回
%0,也就是更新v->counter的值。
- 取值:汇编指令首先从
而这三个步骤在单核情况下就是一条
addl指令,在单核情况下是原子的,addl在执行时不会被打断
在SMP系统下,由于每个核心都有自己的cache,因此通过锁总线的方式来保证addl指令在多核情况下对同一块内存的操作是一个cpu独占的,在读写完成后再通过cache一致性协议同步,上面这个LOCK_PREFIX宏定义了一些前缀,具体什么意思可以参照下面这个博客,总之就是使用lock指令进行了锁总线的操作,从而实现addl指令在多核情况下的原子性
1.2 ARM架构的原子操作底层实现
arm架构会有一些不同,ARMv3至ARMv7支持32位寻址空间。ARMv8-A开始支持64位寻址空间,32位的arm架构和64位的arm架构在实现原子操作时是存在一些指令上的不同的。在ARMv8.1之前,为实现原子操作采用的方法主要是LL/SC(Load-Link/Store-Conditional)。ARMv7中实现LL/SC的指令是LDREX/STREX,其实就是比基础的LDR和STR指令多了一个”EX”,”EX”表示exclusive(独占)。具体说来就是,当用LDREX指令从内存某个地址取出数据放到寄存器后,一个硬件的monitor会将此地址标记为exclusive。
1.2.1 ARM32原子操作
我们先来看ARMV7是如何做的,还是以atomic_add这个宏为例子,ARMV7及以前的代码是放在arch/arm目录下,我们去arch/arm/include/asm/atomic.h中查找:

在此文件中首先定义了一个宏__LINUX_ARM_ARCH__如果ARM的架构版本大于等于6则说明是支持SMP系统的,如果ARM架构的版本小于ARMV7说明是不支持SMP系统的,多核情况下支持锁内存这样的指令,而单核情况下是不支持的,因此原子操作实际上是通过关闭中断来实现的
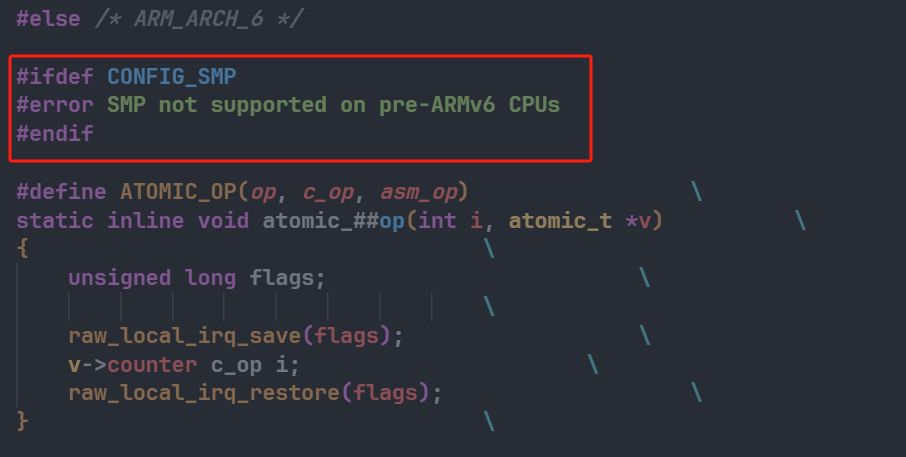
在此文件的下半部分定义了一些宏:
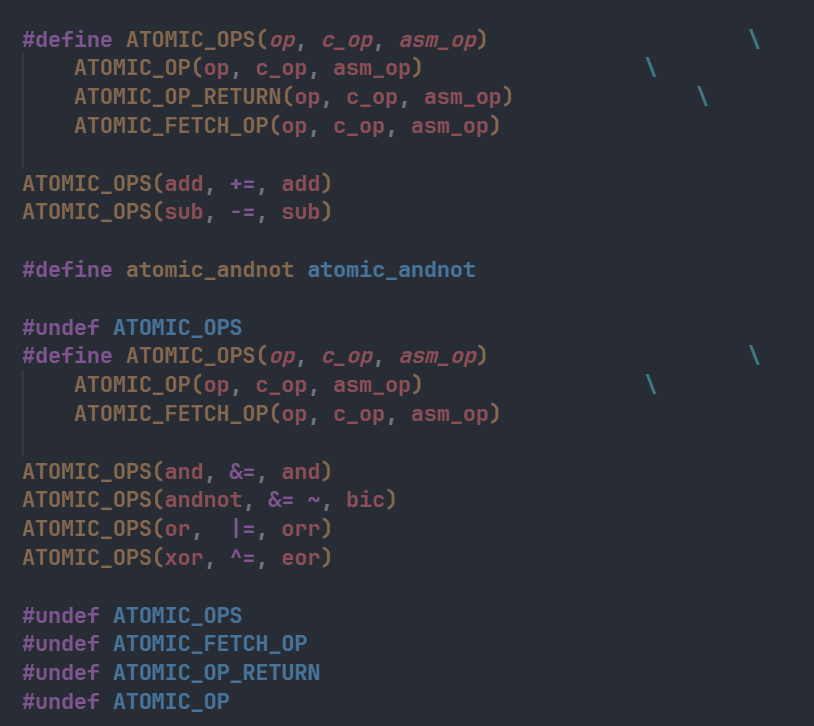
ATOMIC_OPS这个宏展开后会去依次调用ATOMIC_OP,ATOMIC_OP_RETURN,ATOMIC_FETCH_OP,在上面的代码中调用了ATOMIC_OPS(add, +=, add),就相当于:
ATOMIC_OP(add, += , add) |
这三个宏都是在上面定义的,以SMP系统下的ATOMIC_OP为例子:
/* |
展开后这个宏函数的名字就变成了,可以看见就是我们需要的atomic_add函数,其余的宏展开后同理
static inline void atomic_add(int i, atomic_t *v){ |
unsigned long tmp;和int result;定义了两个变量,分别用于存储临时数据和操作结果。prefetchw(&v->counter);用于预取v->counter的写操作,这可能帮助提高性能。定义了一个内联汇编块,用于实现原子操作。
"@ atomic_" #op "\n"是一个注释,标识了操作类型。"ldrex %0, [%3]\n"使用ldrex指令加载v->counter的值到result,这是一个独占读取。"#asm_op %0, %0, %4\n"执行指定的操作,如add,结果存回result。"strex %1, %0, [%3]\n"使用strex尝试将result的新值存回v->counter。如果在此期间v->counter被其他处理器修改过,则strex返回非零值。"teq %1, #0\n"测试strex的结果是否为 0(表示成功)。"bne 1b"如果strex失败(tmp不为 0),则跳回标签1重新执行。
"+Qo" (v->counter)表示v->counter是一个输入输出操作数(既被读也被写)。"r" (&v->counter)和"Ir" (i)分别传入v->counter的地址和整数i作为输入。"cc"表示这段代码会修改条件寄存器。
这段汇编代码的逻辑如下图所示:
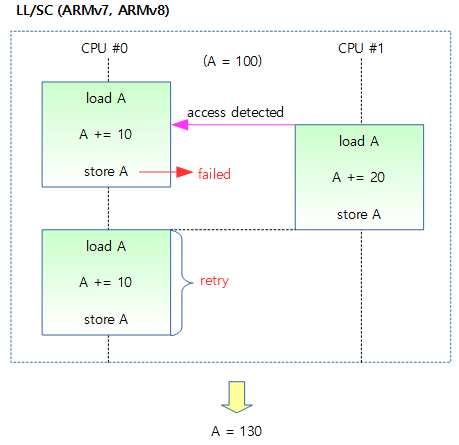
假设CPU A先进行load操作,并标记了变量v所在的内存地址为exclusive,在CPU A进行下一步的store操作之前,CPU B也进行了对变量v的load操作,那么这个内存地址的exclusive就成了CPU B标记的了。之后CPU A使用STREX进行store操作,它会测试store的目标地址的exclusive是不是自己标记的(是否为自己独占),结果不是,那么store失败。接下来CPU B也执行STREX,因为exclusive是自己标记的,所以可以store成功,exclusive标记也同步失效。此时CPU A会再次尝试一轮LL/SC的操作,直到store成功。
而对于非SMP系统即单核系统:
- 可以看见直接使用开关中断的方式来实现
1.2.2 ARM64原子操作
ARM64原子操作相关的代码定义在arch/arm64/include/atomic.h,在此文件的开头有一个包含头文件的操作:
CONFIG_ARM64_LSE_ATOMICS这个宏是在 ARMv8.1 架构中引入的一组增强的原子操作(LSE,Large System Extensions),这些操作提供了更高效的原子指令支持。CONFIG_AS_LSE可能表示汇编器支持LSE指令集。- 因此如果是
ARMv8.1架构以后的使用的是<asm/atomic_lse.h>这个头文件,ARMv8.1以前大于ARMV7的使用的是<asm/atomic_ll_sc.h>头文件
我们先来看<asm/atomic_ll_sc.h>文件即不支持LSE的原子操作是如何实现的:
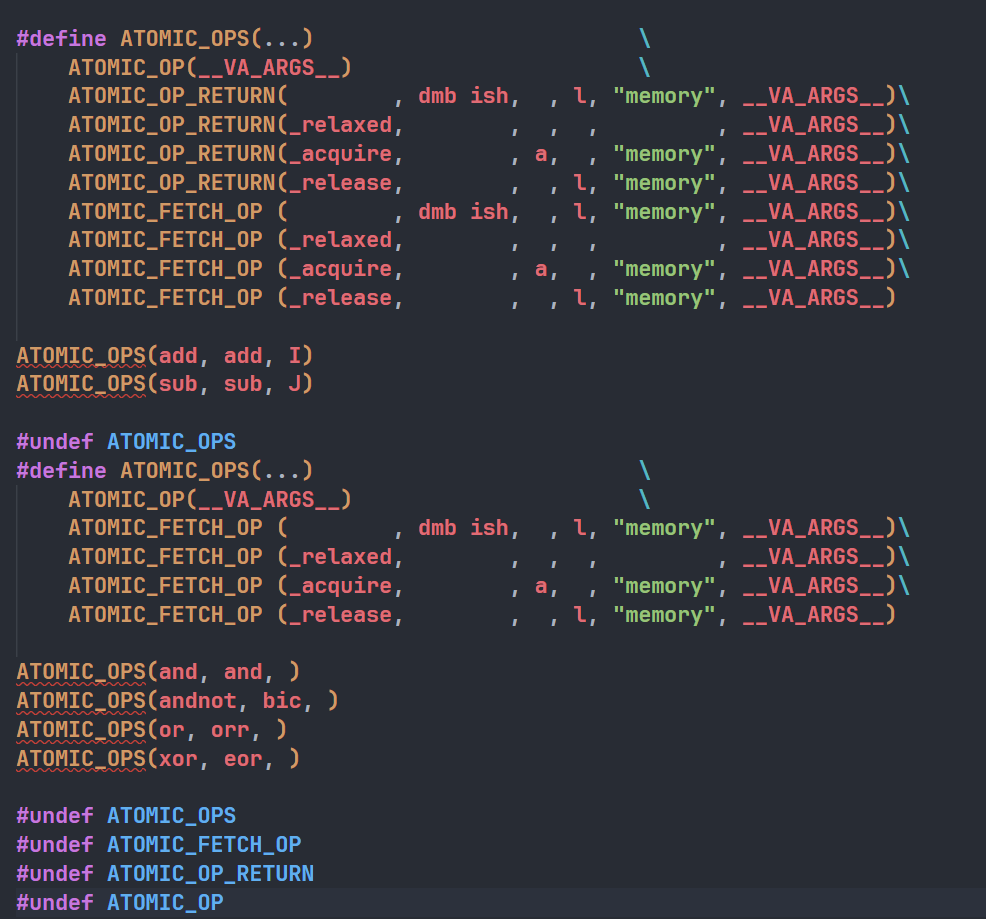
和ARMV7一样调用ATOMIC_OPS(and, and, ),
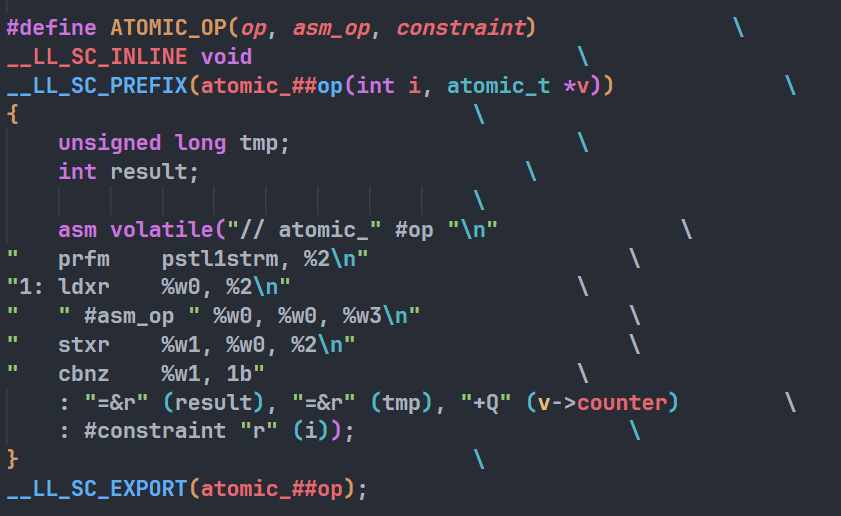
展开后变成:
|
ldxr和ldrex都是实现原子操作的 Load-Exclusive 指令,但它们适用于不同的 ARM 架构版本。汇编指令详细执行原子操作:
prfm pstl1strm, %2:预取指令,为存储预取数据到一级流式存储器。ldxr %w0, %2:使用 Load-Exclusive 指令从v->counter加载数据到寄存器%w0。#asm_op %w0, %w0, %w3:执行如加法、减法等操作,结果存回%w0。stxr %w1, %w0, %2:使用 Store-Exclusive 指令尝试将%w0的值存回v->counter。cbnz %w1, 1b:如果stxr指示存储失败(寄存器%w1不为零),则跳回标签1重新尝试。
寄存器
result和tmp分别用于存储操作的结果和临时数据。约束
"+Q" (v->counter)表示v->counter是一个读写操作数。#constraint "r" (i)表示输入i作为寄存器输入,具体的约束由宏的调用者提供。
对于ARMv8.1 架构及以后支持LSE指令集的原子操作实现需要去查看<asm/atomic_lse.h>,在上面的原子实现中,如果stxr指令失败会导致重试,重试一次还好,如果CPU之间竞争比较激烈,可能导致重试的次数较多,所以从2014年的ARMv8.1开始,ARM推出了用于原子操作的LSE(Large System Extension)指令集扩展,新增的指令包括CAS, SWP和LD
来看看代码:
|
展开后为:
#define __LL_SC_ATOMIC(op) __LL_SC_CALL(atomic_##op) |
寄存器绑定:
- 变量
w0和x1分别绑定到 ARM64 寄存器w0和x1。w0是用来存储整数i,而x1是用来存储指针v的地址。 - 使用
asm关键字显式指定使用哪个寄存器,这有助于在内联汇编代码中直接引用这些寄存器。
内联汇编:
" " #asm_op " %w[i], %[v]\n":这是实际执行的原子操作指令,#asm_op将被替换为传入的汇编操作符,如stadd。- 输出列表 (
[i] "+r" (w0), [v] "+Q" (v->counter)):定义了内联汇编修改的变量。+r表示变量既是输入又是输出,+Q表示内存操作数,也是读写的。 - 输入列表 (
"r" (x1)):提供给汇编的输入。 - 被破坏列表 (
__LL_SC_CLOBBERS):可能是一组被这段内联汇编修改的其他寄存器,以确保调用者能够保存和恢复这些寄存器的状态。
直接一条指令实现了原子操作,类似于x86的lock指令
2.自旋锁
自旋锁(spin lock)是一种非阻塞锁,也就是说,如果某线程需要获取锁,但该锁已经被其他线程占用时,该线程不会被挂起,而是在不断的消耗 CPU 的时间,不停的试图获取锁。
内核中以 spinlock_t 结构体来表示自旋锁,定义在“内核源码/include/linux/spinlock_types.h” 文件中,如下所示
typedef struct spinlock { |
spinlock_t这个结构体实际使用的是raw_spinlock_traw_spinlock_t内部使用的是arch_spinlock_t,一看就是一个和体系结构相关的自旋锁
自旋锁相关 API 函数定义在“内核源码/include/linux/spinlock.h”文件中,部分 API 函数如下所示
| 函数 | 描述 |
|---|---|
| DEFINE_SPINLOCK(spinlock_t lock) | 定义并初始化自旋锁 |
| int spin_lock_init(spinlock_t *lock) | 初始化自旋锁 |
| void spin_lock(spinlock_t *lock) | 获取指定的自旋锁,也叫做加锁 |
| void spin_unlock(spinlock_t *lock) | 释放指定的自旋锁 |
| int spin_trylock(spinlock_t *lock) | 尝试获取指定的自旋锁,如果没有获取到就返回 0 |
| int spin_is_locked(spinlock_t *lock) | 检查指定的自旋锁是否被获取,如果没有被获取就返回非 0,否则返回0 |
自旋锁的使用步骤:
在访问临界资源的时候先申请自旋锁
获取到自旋锁之后就进入临界区,获取不到自旋锁就“原地等待”。
退出临界区的时候要释放自旋锁。
我们要去分析自旋锁的代码实际上就是要去看arch_spinlock_t的相关操作,回到“内核源码/include/linux/spinlock_types.h”的最上面即raw_spinlock_t定义的地方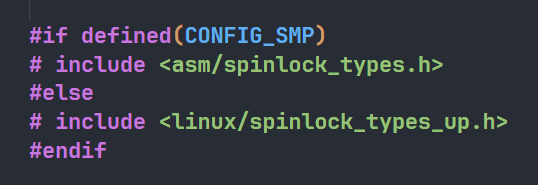
- 如果是
SMP系统使用的是<asm/spinlock_types.h>,否则使用的是<linux/spinlock_types_up.h>
到这里就到了自旋锁的分水岭,单核情况和多核情况自旋锁是完全不同的,这里先引入一个概念,关于抢占式内核与非抢占式内核:
在非抢占式内核中,如果一个进程在内核态运行,其只有在以下两种情况会被切换:
- 其运行完成(返回用户空间)
- 主动让出cpu(即主动调用schedule或内核中的任务阻塞——这同样也会导致调用schedule)
在抢占式内核中,如果一个进程在内核态运行,其只有在以下四种情况会被切换:
- 其运行完成(返回用户空间)
- 主动让出cpu(即主动调用schedule或内核中的任务阻塞——这同样也会导致调用schedule)
- 当从中断处理程序正在执行,且返回内核空间之前(此时可抢占标志premptcount须为0)
- 当内核代码再一次具有可抢占性的时候,如解锁及使能软中断等。
linux内核是一个可抢占的内核, 在单cpu,可抢占内核中,自旋锁实现为“禁止内核抢占”,并不实现“自旋”。禁止内核抢占只是关闭“可抢占标志”,而不是禁止进程切换。显式使用schedule或进程阻塞(此也会导致调用schedule)时,还是会发生进程调度的。这也符合自旋锁的作用,加上自旋锁的线程是不会被阻塞的,禁止抢占会防止线程从运行态被切换。在多cpu,可抢占内核中,自旋锁实现为“禁止内核抢占” + “自旋”。
2.1 单核情况下自旋锁的实现
有了上面的概念我们再来看单核情况下自旋锁的实现,上面说到我们需要去<linux/spinlock_types_up.h>寻找arch_spinlock_t的定义:
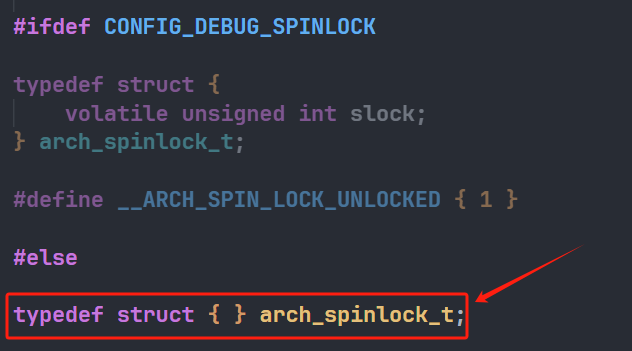
可以看见是一个空的结构体,然后我们来看加锁函数spin_lock,定义在include/linux/spinlock.h中,此函数会去掉用raw_spin_lock的宏,这个宏也在此头文件中,然后会去调用_raw_spin_lock,此宏定义在include/linux/spinlock_api_up.h中,它会去调用__LOCK宏,__LOCK会调用___LOCK
// include/linux/spinlock.h |
- 可以看见先做了
preempt_disable();操作,用于禁止抢占 - 然后执行
__acquire(lock);,可以看见就是将lock置为0,然后(void)(lock);置为空 - 所以在单核情况下自旋锁除了关闭内核抢占,什么都没做
对于锁的释放spin_unlock
// include/linux/spinlock.h |
- 调用
preempt_enable();重新开启cpu的内核抢占
2.2 多核情况下自旋锁的实现
在多核情况下arch_spinlock_t的需要包含<asm/spinlock_types.h>中,这是一个和体系架构相关的头文件,在x86、ARM32、ARM64下的实现是不一样的,
2.2.1 ARM32
首先来看ARM32的实现,用到的头文件为“内核源码/arch/arm/include/asm/spinlock_types.h”
|
arch_spinlock_t结构体内部是一个联合体,简单来说就是存放一个u32类型的数据,把一个u32拆分成两个u16,分别为next和ownerowner表示持有这个数字的线程可以获取自旋锁next表示如果后续再有线程请求获取这个自旋锁,就为此线程分配这个数字
__ARMEB__这个宏是标识大端和小端的next和owner设计的原因是为了保证spinlock的公平性,先申请持有锁的线程先拿到锁,举个例子1.刚开始
owner=next=0;
2.第一个thread获取spinlock,可获取成功,此时owner=0,next=0
3.第二个thread获取spinlock,如果第一个thread 还没有释放spinlock,则next++,next变为1;4.第三个thread获取spinlock,如果第一个thread 还没有释放spinlock,则next++,next变为2;
5.此时第一个thread释放spinlock,则执行
owner++,owner=1;6.虽然此时第二个thread和第三个thread都在等待spinlock,但是因为第二个thread的next=owner,所以第二个thread可以获取到spinlock,第三个thread则继续等待。
这样保证了spinlock的唤醒机制是先到先唤醒,后到后唤醒保证了公平性。
基于上面的设计我们来看一下加锁操作,在内核源码/include/linux/spinlock.h中:
初始化:
// include/linux/spinlock.h |
- 可以看见初始化锁最后会调用到
arch/arm/include/asm/spinlock_types.h文件中的__ARCH_SPIN_LOCK_UNLOCKED来将自旋锁中的.raw_lock成员初始化为0,在上面的自旋锁的定义中arch_spinlock_t raw_lock;最后实际上就是将arch_spinlock_t结构体中的u32变成了0,即初始化时next=0 , owner=0
加锁操作:
// include/linux/spinlock.h |
调用
spin_lock加锁,对于ARM32最终会调用到arch_spin_lockldrex %0, [%3]:将[lock->slock]的值加载到lockval中,并设置一个独占标志。就是加载锁的那个u32的值到lockval中。存储一个锁的值的本地副本lockvaladd %1, %0, %4:将lockval和1 << TICKET_SHIFT相加,结果存储在newval中。TICKET_SHIFT的值为16,即将高16位加一,那么newval的next就加一了strex %2, %1, [%3]:将newval写入到[lock->slock]中,如果成功(即tmp为 0),则表示锁获取成功,否则重试。执行完毕上面的操作后就是将锁的
u32的值的next加一了,然后保存了一个本地的副本值,lockval的next值是上一次未加一的值然后下面有个
while循环会去判断lockval的owner值和next值是否相等,如果不等,则去加载最新的lock的owner的值,上面提到如果有线程释放锁了,会去将lock的owner值加一,因此如果最新的owner值和本地线程维护的next值相等了就说明本地线程可以不用循环等待了在循环内部会调用一个
wfe()函数,这个函数是用于使当前的cpu处于低功耗状态,如果说其他核心上的线程还在持有锁并没有释放,我们可以让当前线程不用一直自旋,直接使其进入低功耗状态,当锁释放时再唤醒
解锁操作:
// include/linux/spinlock.h |
- 可以看见解锁操作就是将
owner的值加一 - 然后唤醒,上面提到其余没有拿到锁的线程会自旋然后进入低功耗状态,调用
dsb_sev();就可以唤醒cpu,因为此时owner的值加一了
2.2.2 ARM64和X86
在ARM64和x86平台下,先要去找arch_spinlock_t的定义,去arch/arm64/include/asm/spinlock_types.h中寻找:
可以看见会去包含:
进入/include/asm-generic/qspinlock_types.h,
typedef struct qspinlock { |
在这里定义了arch_spinlock_t,__LITTLE_ENDIAN用于判断大端和小端,可以看见使用了一个32位的原子变量
来看加锁操作:
// include/linux/spinlock.h |
实现十分复杂,后续再分析……
/** |
3. 信号量
Linux 内核使用 semaphore 结构体来表示信号量,该结构体定义在“内核源码/include/linux/semaphore.h”文件内
/* Please don't access any members of this structure directly */ |
与信号量相关的 API 函数同样定义在 semaphore.h 文件内,部分常用 API 函数如下所示:
| 函数 | 描述 |
|---|---|
DEFINE_SEAMPHORE(name) |
定义信号量,并且设置信号量的值为 1。 |
void sema_init(struct semaphore *sem, int val) |
初始化信号量 sem,设置信号量值为 val。 |
void down(struct semaphore *sem) |
获取信号量,不能被中断打断,如 ctrl+c |
int down_interruptible(struct semaphore *sem) |
获取信号量,可以被中断打断,如 ctrl+c |
void up(struct semaphore *sem) |
释放信号量 |
int down_trylock(struct semaphore *sem); |
尝试获取信号量,如果能获取到信号量就获取,并且返回 0 |
在semaphore 结构体的定义中,包含一个自旋锁,一个计数的count值,一个双向链表
先来看定义信号量的宏以及初始化函数:
// include/linux/semaphore.h |
- 初始化了自旋锁
- 然后初始化了
count值 - 初始化了双向链表,这个链表用于挂载阻塞在此信号量上的线程的结构体指针
加锁函数即down函数,获取一个锁:
// kernel/locking/semaphore.c |
调用
raw_spin_lock_irqsave加锁如果
count的值大于0,则将信号量的count值减一,如果count的值小于等于0,则会去执行__down函数,最终会去调用到__down_common函数,传入的参数为TASK_UNINTERRUPTIBLE和MAX_SCHEDULE_TIMEOUTTASK_UNINTERRUPTIBLE:线程已经进入睡眠状态,且不可被打断MAX_SCHEDULE_TIMEOUT:线程调度超时时间
如果进入了
__down_common函数就说明当前的线程拿不到信号量,那么当前线程应该干嘛呢,肯定不能傻傻的干等,因此当前线程会休眠,当持有信号量的线程释放信号量后再通知阻塞在此信号量的线程从而将其唤醒去执行,__down_common函数就是在做这一件事情首先定了一个
semaphore_waiter,包含一个链表节点和一个task_struct,task_struct可用于代表当前线程,current就代表了当前线程的task_struct的指针struct semaphore_waiter {
struct list_head list;
struct task_struct *task;
bool up;
};
struct semaphore_waiter waiter;
waiter.task = current;
waiter.up = false;然后调用
list_add_tail(&waiter.list, &*sem*->wait_list);将这个semaphore_waiter挂载在信号量的wait_list链表上,因此当持有信号量的线程释放后就可以通过这个等待链表去唤醒其他阻塞的线程,唤醒其实就是将这个bool的up值置为true在
for循环内部,会先去调用signal_pending_state去检测线程在当前状态下是否有信号需要处理,我们出入的进程状态为TASK_UNINTERRUPTIBLE,即在此状态下有信号需要处理也需要返回。然后由于传入的
MAX_SCHEDULE_TIMEOUT是一个很大的值,因此timed_out应该也是不会超时的调用
__set_current_state来设置当前线程的状态raw_spin_unlock_irq解锁,这里为什么要先解锁呢,那是因为下面执行的schedule_timeout会导致当前的线程睡眠,而自旋锁保护的临界资源是不允许睡眠的,schedule_timeout是去执行调度切换当前线程,再次切换回来后会去执行raw_spin_lock_irq加锁操作,然后去判断waiter.up是否为true如果为true说明当前线程被唤醒否则继续执行for循环一直等
调用
raw_spin_unlock_irqrestore开锁
解锁操作,即up函数:
// kernel/locking/semaphore.c |
- 先判断信号量的等待链表是否为空,如果等待的线程为空则直接将
count值加一 - 不为空去执行
__up函数,可以看见在此函数内部就是从等待链表上先取出一个等待的线程,然后从等待链表中删除,将此线程的up置为true,最后去唤醒此线程
最后说一下这里的加锁操作我们使用的是raw_spin_lock_irqsave,它和我们上面讲自旋锁使用的spin_unlock的区别就在于加了irq的会去禁用本地中断,我们以多核系统为例子:
// include/linux/spinlock.h |
- 可以看见只是在
__raw_spin_lock_irq中会去调用local_irq_disable();禁止本地中断,然后最后会去调用arch_spin_lock加锁 - 在使用
spin_lock时要明确知道该锁不会在中断处理程序中使用,如果在中断处理程序中也使用了``spin_lock就会导致死锁,在任何情况下使用spin_lock_irq`都是安全的。因为它既禁止本地中断,又禁止内核抢占。
4. 互斥锁
内核中以mutex结构体来表示互斥体,定义在“内核源码/include/linux/mutex.h”文件中,如下所示:
struct mutex { |
- 可以看见互斥锁的实现其实和信号量类似,不同的是互斥锁在任何时刻只会有一个线程可以持有锁,而信号量可以多个,在互斥锁的内部同样有一个挂载等待线程的链表
wait_list,以及一个原子变量owner - 包含一个互斥锁用于加锁操作
一些和互斥体相关的 API 函数也定义在 mutex.h 文件中,常用 API 函数如下所示
| 函数 | 描述 |
|---|---|
DEFINE_MUTEX(name) |
定义并初始化一个 mutex 变量。 |
void mutex_init(mutex *lock) |
初始化 mutex。 |
void mutex_lock(struct mutex *lock) |
获取 mutex,也就是给 mutex 上锁。 |
void mutex_unlock(struct mutex *lock) |
释放 mutex,也就给 mutex 解锁。 |
int mutex_is_locked(struct mutex *lock) |
判断 mutex 是否被获取,如果是的话就返回1,否则返回0 |
初始化和加锁操作:
// include/linux/mutex.h |
DEFINE_MUTEX宏会去调用__MUTEX_INITIALIZER来定义和初始化一个互斥锁,将互斥锁的owner赋值为0,初始化互斥锁和等待链表mutex_init宏会去调用__mutex_init,同样内部会先将owner的值设置为0,初始化互斥锁,初始化等待链表
加锁操作:
// kernel/locking/mutex.c |
might_sleep();不用管,如果没有调试的需要(没有定义CONFIG_DEBUG_ATOMIC_SLEEP),这个宏/函数什么事情都不,might_sleep就是一个空函数,所以平常看code的时候可以忽略。内核只是用它来提醒开发人员,调用该函数的函数可能会sleep。然后调用
__mutex_trylock_fast(*lock*)去快速加锁fast 部分的代码相对比较简单,主要是两步:
- 获取当前进程的
task_stuct指针,current是当前线程的tcb指针 - 调用
atomic_long_cmpxchg_acquire函数尝试更新lock->owner,这个函数是一个原子操作函数,因为lock->owner是全局变量,所以这里需要用到原子操作。这个接口的定义为:将 p1 (第一个参数)和 p2 作比较,如果相等,则 p1=p3,返回 p2,否则不执行赋值,直接返回 p1,类似于c++的CAS操作
当
lock->owner为 0 时,表示既没有其它进程获取锁也没有等待者,就可以直接获取到锁并返回。否则就代表有其他线程持有锁。此时就需要加上慢锁了- 获取当前进程的
__mutex_lock_slowpath会去调用__mutex_lock,然后调用__mutex_lock_common,如下:/*
* Lock a mutex (possibly interruptible), slowpath:
*/
static __always_inline int __sched
__mutex_lock_common(struct mutex *lock, long state, unsigned int subclass,
struct lockdep_map *nest_lock, unsigned long ip,
struct ww_acquire_ctx *ww_ctx, const bool use_ww_ctx)
{
struct mutex_waiter waiter;
struct ww_mutex *ww;
int ret;
if (!use_ww_ctx)
ww_ctx = NULL;
might_sleep();
ww = container_of(lock, struct ww_mutex, base);
if (ww_ctx) {
if (unlikely(ww_ctx == READ_ONCE(ww->ctx)))
return -EALREADY;
/*
* Reset the wounded flag after a kill. No other process can
* race and wound us here since they can't have a valid owner
* pointer if we don't have any locks held.
*/
if (ww_ctx->acquired == 0)
ww_ctx->wounded = 0;
}
preempt_disable();
mutex_acquire_nest(&lock->dep_map, subclass, 0, nest_lock, ip);
if (__mutex_trylock(lock) ||
mutex_optimistic_spin(lock, ww_ctx, NULL)) {
/* got the lock, yay! */
lock_acquired(&lock->dep_map, ip);
if (ww_ctx)
ww_mutex_set_context_fastpath(ww, ww_ctx);
preempt_enable();
return 0;
}
spin_lock(&lock->wait_lock);
/*
* After waiting to acquire the wait_lock, try again.
*/
if (__mutex_trylock(lock)) {
if (ww_ctx)
__ww_mutex_check_waiters(lock, ww_ctx);
goto skip_wait;
}
debug_mutex_lock_common(lock, &waiter);
lock_contended(&lock->dep_map, ip);
if (!use_ww_ctx) {
/* add waiting tasks to the end of the waitqueue (FIFO): */
__mutex_add_waiter(lock, &waiter, &lock->wait_list);
waiter.ww_ctx = MUTEX_POISON_WW_CTX;
} else {
/*
* Add in stamp order, waking up waiters that must kill
* themselves.
*/
ret = __ww_mutex_add_waiter(&waiter, lock, ww_ctx);
if (ret)
goto err_early_kill;
waiter.ww_ctx = ww_ctx;
}
waiter.task = current;
set_current_state(state);
for (;;) {
bool first;
/*
* Once we hold wait_lock, we're serialized against
* mutex_unlock() handing the lock off to us, do a trylock
* before testing the error conditions to make sure we pick up
* the handoff.
*/
if (__mutex_trylock(lock))
goto acquired;
/*
* Check for signals and kill conditions while holding
* wait_lock. This ensures the lock cancellation is ordered
* against mutex_unlock() and wake-ups do not go missing.
*/
if (unlikely(signal_pending_state(state, current))) {
ret = -EINTR;
goto err;
}
if (ww_ctx) {
ret = __ww_mutex_check_kill(lock, &waiter, ww_ctx);
if (ret)
goto err;
}
spin_unlock(&lock->wait_lock);
schedule_preempt_disabled();
first = __mutex_waiter_is_first(lock, &waiter);
if (first)
__mutex_set_flag(lock, MUTEX_FLAG_HANDOFF);
set_current_state(state);
/*
* Here we order against unlock; we must either see it change
* state back to RUNNING and fall through the next schedule(),
* or we must see its unlock and acquire.
*/
if (__mutex_trylock(lock) ||
(first && mutex_optimistic_spin(lock, ww_ctx, &waiter)))
break;
spin_lock(&lock->wait_lock);
}
spin_lock(&lock->wait_lock);
acquired:
__set_current_state(TASK_RUNNING);
if (ww_ctx) {
/*
* Wound-Wait; we stole the lock (!first_waiter), check the
* waiters as anyone might want to wound us.
*/
if (!ww_ctx->is_wait_die &&
!__mutex_waiter_is_first(lock, &waiter))
__ww_mutex_check_waiters(lock, ww_ctx);
}
__mutex_remove_waiter(lock, &waiter);
debug_mutex_free_waiter(&waiter);
skip_wait:
/* got the lock - cleanup and rejoice! */
lock_acquired(&lock->dep_map, ip);
if (ww_ctx)
ww_mutex_lock_acquired(ww, ww_ctx);
spin_unlock(&lock->wait_lock);
preempt_enable();
return 0;
err:
__set_current_state(TASK_RUNNING);
__mutex_remove_waiter(lock, &waiter);
err_early_kill:
spin_unlock(&lock->wait_lock);
debug_mutex_free_waiter(&waiter);
mutex_release(&lock->dep_map, 1, ip);
preempt_enable();
return ret;
}关于此函数的分析请参考如下博文,后续有时间再去看代码
参考链接
 微信
微信 支付宝
支付宝
![ARM64-Trust-Firmware[3]-BL1解析](/2026/01/24/ARM64-Trust-Firmware-3-BL1%E8%A7%A3%E6%9E%90/17692290470595.png)
![ARM64-Trust-Firmware[2]-启动ATF](/2026/01/24/ARM64-Trust-Firmware-2-%E5%90%AF%E5%8A%A8ATF/17692287555201.png)
![ARM64-Trust-Firmware[1]-ARM安全架构](/2026/01/24/ARM64-Trust-Firmware-1-ARM%E5%AE%89%E5%85%A8%E6%9E%B6%E6%9E%84/17692284856153.png)
![Xhyper剖析[6]--中断虚拟化](/2026/01/20/Xhyper%E5%89%96%E6%9E%90-6-%E4%B8%AD%E6%96%AD%E8%99%9A%E6%8B%9F%E5%8C%96/17689244713913.png)
![Xhyper剖析[5]--MMIO虚拟化](/2026/01/20/Xhyper%E5%89%96%E6%9E%90-5-MMIO%E8%99%9A%E6%8B%9F%E5%8C%96/17689243819381.png)