1.源码 在cyber/base/unbounded_queue.h中实现了一个无界无锁队列的模板类,通过c++提供的原子操作来确保线程安全,代码如下:
template <typename T>class UnboundedQueue { public : UnboundedQueue () { Reset (); } UnboundedQueue& operator =(const UnboundedQueue& other) = delete ; UnboundedQueue (const UnboundedQueue& other) = delete ; ~UnboundedQueue () { Destroy (); } void Clear () Destroy (); Reset (); } void Enqueue (const T& element) auto node = new Node (); node->data = element; Node* old_tail = tail_.load (); while (true ) { if (tail_.compare_exchange_strong (old_tail, node)) { old_tail->next = node; old_tail->release (); size_.fetch_add (1 ); break ; } } } bool Dequeue (T* element) Node* old_head = head_.load (); Node* head_next = nullptr ; do { head_next = old_head->next; if (head_next == nullptr ) { return false ; } } while (!head_.compare_exchange_strong (old_head, head_next)); *element = head_next->data; size_.fetch_sub (1 ); old_head->release (); return true ; } size_t Size () return size_.load (); } bool Empty () return size_.load () == 0 ; } private : struct Node { T data; std::atomic<uint32_t > ref_count; Node* next = nullptr ; Node () { ref_count.store (2 ); } void release () ref_count.fetch_sub (1 ); if (ref_count.load () == 0 ) { delete this ; } } }; void Reset () auto node = new Node (); head_.store (node); tail_.store (node); size_.store (0 ); } void Destroy () auto ite = head_.load (); Node* tmp = nullptr ; while (ite != nullptr ) { tmp = ite->next; delete ite; ite = tmp; } } std::atomic<Node*> head_; std::atomic<Node*> tail_; std::atomic<size_t > size_; };
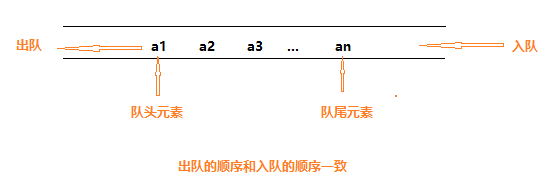
2.无界无锁队列的实现 队列(queue)是只允许在一端进行插入操作,在另一端进行删除操作的线性表,简称“队”。队列是一种先进先出(First In First Out)的线性表,简称FIFO。允许插入的一端称为队尾(rear),允许删除的一端称为队头(front)。向队列中插入新的数据元素称为入队,新入队的元素就成为了队列的队尾元素。从队列中删除队头元素称为出队,其后继元素成为新的队头元素。
队列作为一种特殊的线性表,也同样存在两种存储结构:顺序存储结构和链式存储结构,可以分别用数组和链表来实现队列。
在cyberrt中是采用链式结构来实现的,通过链表来进行维护,看上面的代码,先看Node的组成:
Node中的成员包含一个模板类的数据data,一个指向下一个节点的指针和一个用于引用计数的count值,release函数用于释放此节点。
UnboundedQueue内部有三个成员,它的构造函数如下:
UnboundedQueue () { Reset (); } void Reset () auto node = new Node (); head_.store (node); tail_.store (node); size_.store (0 ); } std::atomic<Node*> head_; std::atomic<Node*> tail_; std::atomic<size_t > size_;
head_即是队列的头节点指针,tail_是队列的尾节点指针,size_是节点的个数,这三个变量都是原子类型,保证了在多线程时操作这三个变量时都是线程安全的。
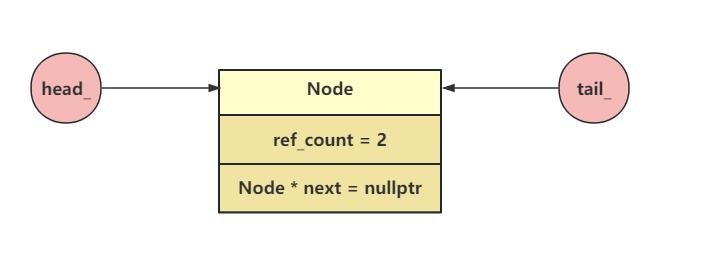
当UnboundedQueue创建时会去调用Reset()函数,Reset()函数会去new一个Node对象,在Node的构造函数中会将ref_count的值设置为2,因为在队列初始化时头指针和尾指针都指向了同一个节点,所以ref_count=2
再来看像队列添加元素的函数void Enqueue(const T& element),
void Enqueue (const T& element) auto node = new Node (); node->data = element; Node* old_tail = tail_.load (); while (true ) { if (tail_.compare_exchange_strong (old_tail, node)) { old_tail->next = node; old_tail->release (); size_.fetch_add (1 ); break ; } } }
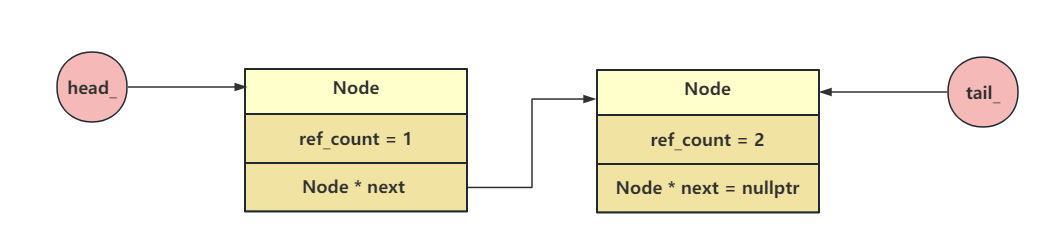
首先同样会新建一个Node,然后对新建的Node的data赋值,我们知道向队列插入元素是在尾部添加,这里使用了一个compare_exchange_strong函数来将tail与old_tail进行比较,如果是同一个则将tail的替换成新建的这个node,然后现在队列的尾部指针就是新建这个node了,这个compare_exchange_strong写的非常巧妙,如果没有发生多线程竞争的话,compare_exchange_strong返回true ,意味着循环一次就结束,tail_的值被设为了node。因为compare_exchange_strong是线程安全的。
可以看见当尾插一个新的节点后上一个节点的引用计数就变成了1,因为调用了release()函数,release()中会对节点引用计数减一,同时如果此节点的引用计数变成了0则销毁此节点释放内存
void release () ref_count.fetch_sub (1 ); if (ref_count.load () == 0 ) { delete this ; } }
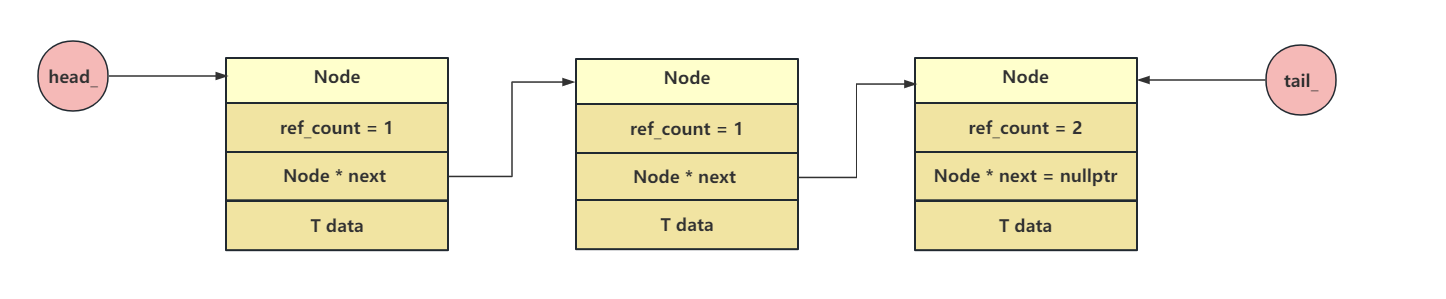
队列的整体结构如下:尾部节点的引用计数始终是2,链表里面所有成员的引用计数都是1。
然后来看从队列中取出数据的函数,取出数据时就是从头部取了。
bool Dequeue (T* element) Node* old_head = head_.load (); Node* head_next = nullptr ; do { head_next = old_head->next; if (head_next == nullptr ) { return false ; } } while (!head_.compare_exchange_strong (old_head, head_next)); *element = head_next->data; size_.fetch_sub (1 ); old_head->release (); return true ; }
逻辑很简单,就是将之前的头指针指向第二个节点,同样使用了compare_exchange_strong来保证线程安全,取出数据后之前的头节点就没用了因此调用release()函数去删除这个节点。
然后最后是队列的销毁函数,这个函数就比较简单了:
void Destroy () auto ite = head_.load (); Node* tmp = nullptr ; while (ite != nullptr ) { tmp = ite->next; delete ite; ite = tmp; } }
从头节点开始遍历,依次删除节点,直到遍历到最后一个节点,因为最后一个节点的next指针指向了nullptr,所以到此停止。
参考链接


 微信
微信 支付宝
支付宝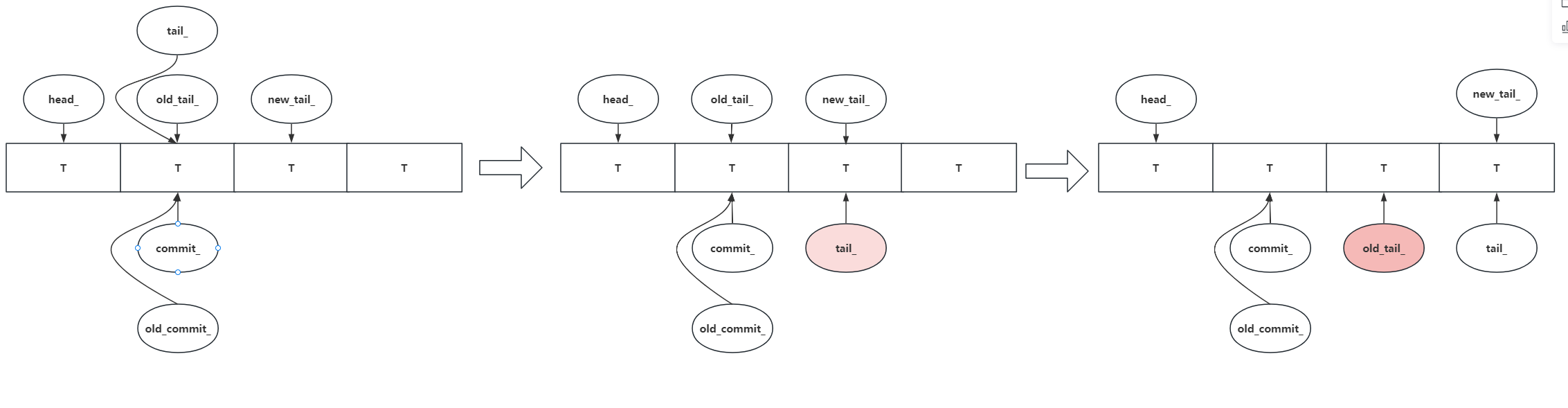
![ARM64-Trust-Firmware[3]-BL1解析](/2026/01/24/ARM64-Trust-Firmware-3-BL1%E8%A7%A3%E6%9E%90/17692290470595.png)
![ARM64-Trust-Firmware[2]-启动ATF](/2026/01/24/ARM64-Trust-Firmware-2-%E5%90%AF%E5%8A%A8ATF/17692287555201.png)
![ARM64-Trust-Firmware[1]-ARM安全架构](/2026/01/24/ARM64-Trust-Firmware-1-ARM%E5%AE%89%E5%85%A8%E6%9E%B6%E6%9E%84/17692284856153.png)
![Xhyper剖析[6]--中断虚拟化](/2026/01/20/Xhyper%E5%89%96%E6%9E%90-6-%E4%B8%AD%E6%96%AD%E8%99%9A%E6%8B%9F%E5%8C%96/17689244713913.png)
![Xhyper剖析[5]--MMIO虚拟化](/2026/01/20/Xhyper%E5%89%96%E6%9E%90-5-MMIO%E8%99%9A%E6%8B%9F%E5%8C%96/17689243819381.png)