1. 源码 源码目录:cyber/base/atomic_hash_map.h
template <typename K, typename V, std::size_t TableSize = 128 , typename std::enable_if<std::is_integral<K>::value && (TableSize & (TableSize - 1 )) == 0 , int >::type = 0 > class AtomicHashMap { public : AtomicHashMap () : capacity_ (TableSize), mode_num_ (capacity_ - 1 ) {} AtomicHashMap (const AtomicHashMap &other) = delete ; AtomicHashMap &operator =(const AtomicHashMap &other) = delete ; bool Has (K key) uint64_t index = key & mode_num_; return table_[index].Has (key); } bool Get (K key, V **value) uint64_t index = key & mode_num_; return table_[index].Get (key, value); } bool Get (K key, V *value) uint64_t index = key & mode_num_; V *val = nullptr ; bool res = table_[index].Get (key, &val); if (res) { *value = *val; } return res; } void Set (K key) uint64_t index = key & mode_num_; table_[index].Insert (key); } void Set (K key, const V &value) uint64_t index = key & mode_num_; table_[index].Insert (key, value); } void Set (K key, V &&value) uint64_t index = key & mode_num_; table_[index].Insert (key, std::forward<V>(value)); } private : struct Entry { Entry () {} explicit Entry (K key) : key(key) { value_ptr.store (new V (), std::memory_order_release); } Entry (K key, const V &value) : key (key) { value_ptr.store (new V (value), std::memory_order_release); } Entry (K key, V &&value) : key (key) { value_ptr.store (new V (std::forward<V>(value)), std::memory_order_release); } ~Entry () { delete value_ptr.load (std::memory_order_acquire); } K key = 0 ; std::atomic<V *> value_ptr = {nullptr }; std::atomic<Entry *> next = {nullptr }; }; class Bucket { public : Bucket () : head_ (new Entry ()) {} ~Bucket () { Entry *ite = head_; while (ite) { auto tmp = ite->next.load (std::memory_order_acquire); delete ite; ite = tmp; } } bool Has (K key) Entry *m_target = head_->next.load (std::memory_order_acquire); while (Entry *target = m_target) { if (target->key < key) { m_target = target->next.load (std::memory_order_acquire); continue ; } else { return target->key == key; } } return false ; } bool Find (K key, Entry **prev_ptr, Entry **target_ptr) Entry *prev = head_; Entry *m_target = head_->next.load (std::memory_order_acquire); while (Entry *target = m_target) { if (target->key == key) { *prev_ptr = prev; *target_ptr = target; return true ; } else if (target->key > key) { *prev_ptr = prev; *target_ptr = target; return false ; } else { prev = target; m_target = target->next.load (std::memory_order_acquire); } } *prev_ptr = prev; *target_ptr = nullptr ; return false ; } void Insert (K key, const V &value) Entry *prev = nullptr ; Entry *target = nullptr ; Entry *new_entry = nullptr ; V *new_value = nullptr ; while (true ) { if (Find (key, &prev, &target)) { if (!new_value) { new_value = new V (value); } auto old_val_ptr = target->value_ptr.load (std::memory_order_acquire); if (target->value_ptr.compare_exchange_strong ( old_val_ptr, new_value, std::memory_order_acq_rel, std::memory_order_relaxed)) { delete old_val_ptr; if (new_entry) { delete new_entry; new_entry = nullptr ; } return ; } continue ; } else { if (!new_entry) { new_entry = new Entry (key, value); } new_entry->next.store (target, std::memory_order_release); if (prev->next.compare_exchange_strong (target, new_entry, std::memory_order_acq_rel, std::memory_order_relaxed)) { if (new_value) { delete new_value; new_value = nullptr ; } return ; } } } } void Insert (K key, V &&value) Entry *prev = nullptr ; Entry *target = nullptr ; Entry *new_entry = nullptr ; V *new_value = nullptr ; while (true ) { if (Find (key, &prev, &target)) { if (!new_value) { new_value = new V (std::forward<V>(value)); } auto old_val_ptr = target->value_ptr.load (std::memory_order_acquire); if (target->value_ptr.compare_exchange_strong ( old_val_ptr, new_value, std::memory_order_acq_rel, std::memory_order_relaxed)) { delete old_val_ptr; if (new_entry) { delete new_entry; new_entry = nullptr ; } return ; } continue ; } else { if (!new_entry) { new_entry = new Entry (key, value); } new_entry->next.store (target, std::memory_order_release); if (prev->next.compare_exchange_strong (target, new_entry, std::memory_order_acq_rel, std::memory_order_relaxed)) { if (new_value) { delete new_value; new_value = nullptr ; } return ; } } } } void Insert (K key) Entry *prev = nullptr ; Entry *target = nullptr ; Entry *new_entry = nullptr ; V *new_value = nullptr ; while (true ) { if (Find (key, &prev, &target)) { if (!new_value) { new_value = new V (); } auto old_val_ptr = target->value_ptr.load (std::memory_order_acquire); if (target->value_ptr.compare_exchange_strong ( old_val_ptr, new_value, std::memory_order_acq_rel, std::memory_order_relaxed)) { delete old_val_ptr; if (new_entry) { delete new_entry; new_entry = nullptr ; } return ; } continue ; } else { if (!new_entry) { new_entry = new Entry (key); } new_entry->next.store (target, std::memory_order_release); if (prev->next.compare_exchange_strong (target, new_entry, std::memory_order_acq_rel, std::memory_order_relaxed)) { if (new_value) { delete new_value; new_value = nullptr ; } return ; } } } } bool Get (K key, V **value) Entry *prev = nullptr ; Entry *target = nullptr ; if (Find (key, &prev, &target)) { *value = target->value_ptr.load (std::memory_order_acquire); return true ; } return false ; } Entry *head_; }; private : Bucket table_[TableSize]; uint64_t capacity_; uint64_t mode_num_; };
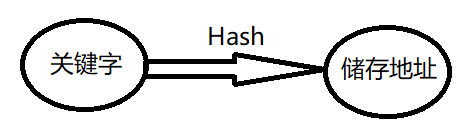
2. 无锁哈希表的实现 散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在存储器存储位置的数据结构。 也就是说,它通过计算出一个键值的函数,将所需查询的数据映射到表中一个位置来让人访问,这加快了查找速度。 这个映射函数称做散列函数,存放记录的数组称做散列表。
给定一个键值K,通过一个函数计算出了这个K在内存中对应值的存储位置,那个这个函数就被称为哈希函数:
这里举个例子:
假如我们一共有 50 人参加学校的数学竞赛,然后我们为每个学生分配一个编号,依次是 1 到 50.
如果我们想要快速知道编号对应学生的信息,我们就可以用一个数组来存放学生的信息,编号为 1 的放到数组下标为 1 的位置,编号为 2 的放到数组下标为 2 的位置,依次类推。
现在如果我们想知道编号为 20 的学生的信息,我们只需要把数组下标为 20 的元素取出来就可以了,时间复杂度为 O(1),是不是效率非常高呢。
但是这些学生肯定来自不同的年级和班级,为了包含更详细的信息,我们在原来编号前边加上年级和班级的信息,比如 030211 ,03 表示年级,02 表示班级,11 原来的编号,这样我们该怎么存储学生的信息,才能够像原来一样使用下标快速查找学生的信息呢?
思路还是和原来一样,我们通过编号作为下标来储存,但是现在编号多出了年级和班级的信息怎么办呢,我们只需要截取编号的后两位作为数组下标来储存就可以了。
这个过程就是典型的散列思想。其中,参赛学生的编号我们称之为键(key),我们用它来标识一个学生。然后我们通过一个方法(比如上边的截取编号最后两位数字)把编号转变为数组下标,这个方法叫做散列函数(哈希函数),通过散列函数得到的值叫做散列值(哈希值)
我们自己在设计散列函数的函数时应该遵循什么规则呢?
得到的散列值是一个非负整数
两个相同的键,通过散列函数计算出的散列值也相同
两个不同的键,计算出的散列值不同
虽然我们在设计的时候要求满足以上三条要求,但对于第三点很难保证所有不同的建都被计算出不同的散列值。有可能不同的建会计算出相同的值,这叫做哈希冲突。为了解决这个冲突,可以将散列函数计算得到相同值得key放到同一个链表中,这也是CyberRt中散列表的做法:
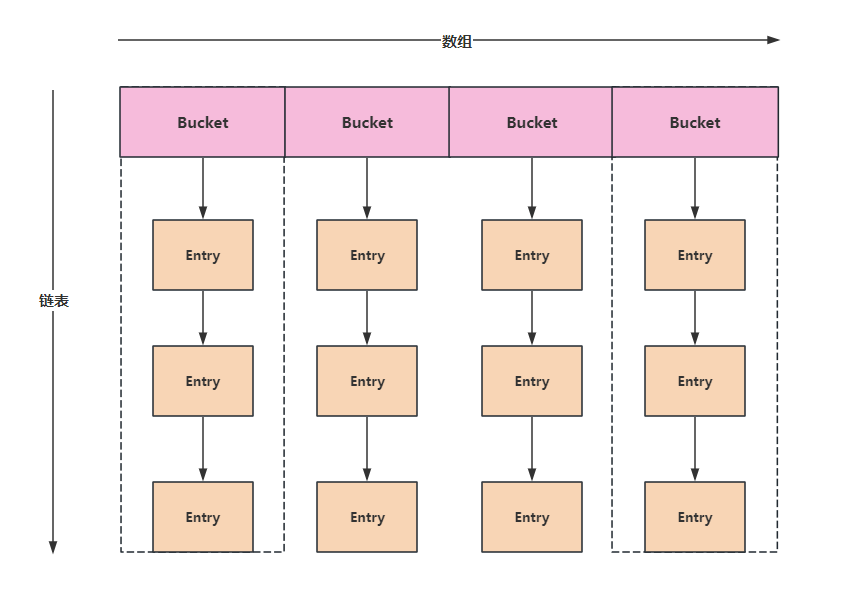
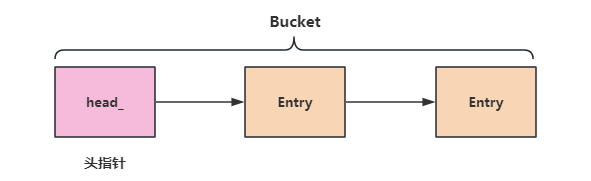
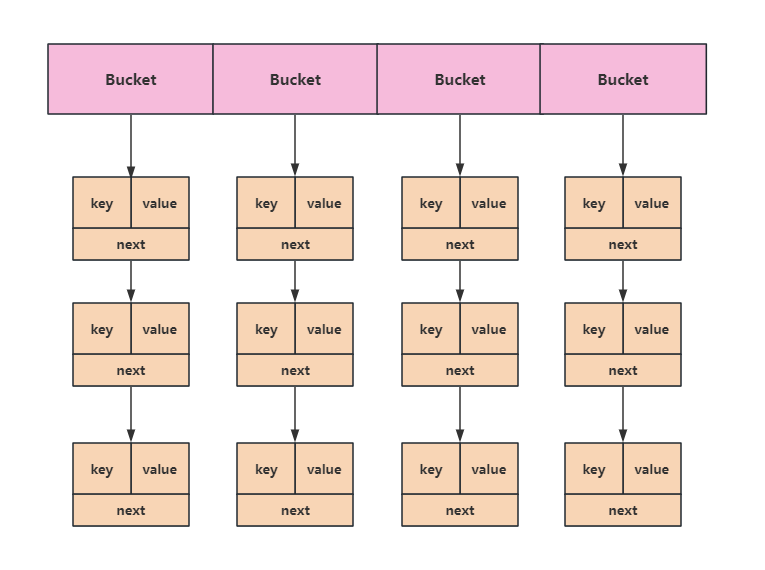
因此散列表就是一个数组,只不过数组中的每个元素都是一个链表,这个链表我们称为一个Bucket,就是一个篮子。Bucket中链表的节点我们用Entry来进行描述。
我们先来看Entry的定义:
struct Entry { Entry () {} explicit Entry (K key) : key(key) { value_ptr.store (new V (), std::memory_order_release); } Entry (K key, const V &value) : key (key) { value_ptr.store (new V (value), std::memory_order_release); } Entry (K key, V &&value) : key (key) { value_ptr.store (new V (std::forward<V>(value)), std::memory_order_release); } ~Entry () { delete value_ptr.load (std::memory_order_acquire); } K key = 0 ; std::atomic<V *> value_ptr = {nullptr }; std::atomic<Entry *> next = {nullptr }; };
每个Entry存储了一个数据指针和指向下一个Entry的指针,他们都是原子变量,在这份源码中,定义说这个键的类型必须为整形,因此K key = 0,里面提供了四个构造函数。
然后是Bucket的定义:Bucket是一个链表,对链表中的每一个节点的操作都是原子的。
在散列表中放入键值后,散列表就长下面这样子了:哈希值相同的键放在同一个Bucket里,同一个Bucket中键的排列依次往下接就行
在Bucket中查找key:根据key挨个对Entry中的key值进行比较,如果找到了就返回true,没找到就返回false
bool Has (K key) Entry *m_target = head_->next.load (std::memory_order_acquire); while (Entry *target = m_target) { if (target->key < key) { m_target = target->next.load (std::memory_order_acquire); continue ; } else { return target->key == key; } } return false ; }
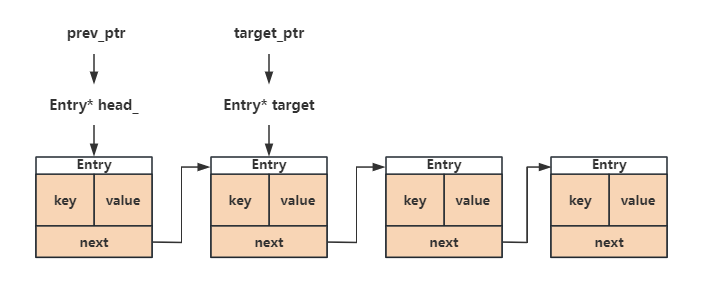
在Bucket中查找key对应的那个Entry:从头节点开始遍历,只要m_target不是null_ptr,循环就会继续执行,如果有对应的key值,将通过prev_ptr和target_ptr参数返回查找结果。prev_ptr和target_ptr都是二级指针,都指向了一个Entry*。如果target指向的那个Entry中的key值大于传入的这个key值,同时又不相等,说明这个key值的大小位于prev和target之间,从这里我们可以猜测,拥有相同哈希值的key在同一个Bucket中的排列是按照从小到大的顺序排的
bool Find (K key, Entry **prev_ptr, Entry **target_ptr) Entry *prev = head_; Entry *m_target = head_->next.load (std::memory_order_acquire); while (Entry *target = m_target) { if (target->key == key) { *prev_ptr = prev; *target_ptr = target; return true ; } else if (target->key > key) { *prev_ptr = prev; *target_ptr = target; return false ; } else { prev = target; m_target = target->next.load (std::memory_order_acquire); } } *prev_ptr = prev; *target_ptr = nullptr ; return false ; }
在Bucket中根据键值插入对应的value:首先调用上面的find函数去查找Bucket中是否存在key,如果存在则新建一个value,然后通过cas操作去修改此Entry中的value值。如果在Bucket中没有找到这个key,说明需要新建一个Entry,需要将这个new_entry插入到prev和target之间,这里也是原子操作。其余两个插入函数同理,只是入参不一样。
void Insert (K key, const V &value) Entry *prev = nullptr ; Entry *target = nullptr ; Entry *new_entry = nullptr ; V *new_value = nullptr ; while (true ) { if (Find (key, &prev, &target)) { if (!new_value) { new_value = new V (value); } auto old_val_ptr = target->value_ptr.load (std::memory_order_acquire); if (target->value_ptr.compare_exchange_strong ( old_val_ptr, new_value, std::memory_order_acq_rel, std::memory_order_relaxed)) { delete old_val_ptr; if (new_entry) { delete new_entry; new_entry = nullptr ; } return ; } continue ; } else { if (!new_entry) { new_entry = new Entry (key, value); } new_entry->next.store (target, std::memory_order_release); if (prev->next.compare_exchange_strong (target, new_entry, std::memory_order_acq_rel, std::memory_order_relaxed)) { if (new_value) { delete new_value; new_value = nullptr ; } return ; } } } }
最后是根据key值拿到value的函数,也是通过Find函数去找,如果找到了则赋值,没找到就返回false
bool Get (K key, V **value) Entry *prev = nullptr ; Entry *target = nullptr ; if (Find (key, &prev, &target)) { *value = target->value_ptr.load (std::memory_order_acquire); return true ; } return false ; }
有了Entry和Bucket之后我们来看一下AtomicHashMap的实现:
template <typename K, typename V, std::size_t TableSize = 128 , typename std::enable_if<std::is_integral<K>::value && (TableSize & (TableSize - 1 )) == 0 , int >::type = 0 > class AtomicHashMap { public : AtomicHashMap () : capacity_ (TableSize), mode_num_ (capacity_ - 1 ) {} AtomicHashMap (const AtomicHashMap &other) = delete ; AtomicHashMap &operator =(const AtomicHashMap &other) = delete ; bool Has (K key) uint64_t index = key & mode_num_; return table_[index].Has (key); } bool Get (K key, V **value) uint64_t index = key & mode_num_; return table_[index].Get (key, value); } bool Get (K key, V *value) uint64_t index = key & mode_num_; V *val = nullptr ; bool res = table_[index].Get (key, &val); if (res) { *value = *val; } return res; } void Set (K key) uint64_t index = key & mode_num_; table_[index].Insert (key); } void Set (K key, const V &value) uint64_t index = key & mode_num_; table_[index].Insert (key, value); } void Set (K key, V &&value) uint64_t index = key & mode_num_; table_[index].Insert (key, std::forward<V>(value)); } private : Bucket table_[TableSize]; uint64_t capacity_; uint64_t mode_num_; }
首先模板操作就很有意思:
<typename K, typename V, std::size_t TableSize = 128, ...>: 定义模板的参数列表。K 和 V 是模板的键和值类型,TableSize 是哈希表的大小,默认为 128。typename std::enable_if<...>::type = 0: 使用 std::enable_if 实现模板的部分特化。这里检查是否 K 是整数类型(std::is_integral<K>::value)并且 TableSize 是 2 的幂((TableSize & (TableSize - 1)) == 0)。如果条件为真,则模板参数 int 被设置为 0,否则,此模板不可用。这里也是用到了c++的SFINAE特性
TableSize & (TableSize - 1) 是一个位运算操作,用于检查一个数是否是2的幂。
如果一个数是2的幂,那么它的二进制表示中只有一个位是1,其余位都是0。
如果减去1,所有的1都变成0,而低位的0都变成1。
通过使用按位与(&)操作,只有在两个相应的位都是1时结果才是1。因此,如果 TableSize 是2的幂,那么 TableSize & (TableSize - 1) 将等于0。
这个检查在哈希表的实现中经常用来确保哈希表的大小是2的幂,这有助于提高散列函数的效果,使得键在哈希表中更均匀地分布。
AtomicHashMap类的内部定义了一个Bucket table_[TableSize]的数组,哈希函数其实就是线性的取余,里面对哈希表的操作也比较简单,就是先去根据键的值取余去拿到对应的Bucket,然后再去Buket中操作
参考链接

 微信
微信 支付宝
支付宝
![ARM64-Trust-Firmware[3]-BL1解析](/2026/01/24/ARM64-Trust-Firmware-3-BL1%E8%A7%A3%E6%9E%90/17692290470595.png)
![ARM64-Trust-Firmware[2]-启动ATF](/2026/01/24/ARM64-Trust-Firmware-2-%E5%90%AF%E5%8A%A8ATF/17692287555201.png)
![ARM64-Trust-Firmware[1]-ARM安全架构](/2026/01/24/ARM64-Trust-Firmware-1-ARM%E5%AE%89%E5%85%A8%E6%9E%B6%E6%9E%84/17692284856153.png)
![Xhyper剖析[6]--中断虚拟化](/2026/01/20/Xhyper%E5%89%96%E6%9E%90-6-%E4%B8%AD%E6%96%AD%E8%99%9A%E6%8B%9F%E5%8C%96/17689244713913.png)
![Xhyper剖析[5]--MMIO虚拟化](/2026/01/20/Xhyper%E5%89%96%E6%9E%90-5-MMIO%E8%99%9A%E6%8B%9F%E5%8C%96/17689243819381.png)