
Linux内核启动流程分析
Linux内核启动流程分析
我在学习Linux驱动的时候总感觉蒙着一层雾,让我看不清Linux内核的核心,Linux内核有很多子系统,我觉得有必要先从Linux Kernel的启动去宏观的看一下各个子系统是哪个时刻被启动的,我主要以ARM64为例子来分析Linux 内核的启动流程。我们知道在Linux内核启动之前是uboot,uboot会做一些初始化工作,如初始化ddr,我使用的内核源码为迅为电子提供的RK3588的linux SDK,内核版本为5.10.198
1. 内核链接文件
内核编译后生成的目标文件是ELF格式的vmlinux,vmlinux文件是各个源代码按照vmlinux.lds设定的规则,链接后得到的Object文件,并不是一个可执行的文件,不能在ARM平台上运行;通常会对其压缩,生成zImage或bzImage;通常内核映像以压缩格式存储,并不是一个可执行的内核;因此内核阶段需要先对内核映像自解压,他们的文件头部打包有解压缩程序
Linux内核的链接文件目录在arch/arm64/kernel/vmlinux.lds.S,内核在编译时会根据vmlinux.lds.S生成vmlinux.lds,vmlinux.lds就是内核最后的链接脚本,会用于链接生成内核镜像vmlinux
//arch/arm64/kernel/vmlinux.lds.S |
在此文件的开头指定了输出的架构以及内核入口地址为
_textOUTPUT_ARCH(aarch64)
ENTRY(_text)_text是代码段的起始地址,定义在下面的SECTIONS部分,可以看见_text即为.head_text段,地址为:KIMAGE_VADDR + TEXT_OFFSET,这两个宏定义在arch/arm64/include/asm/memory.h中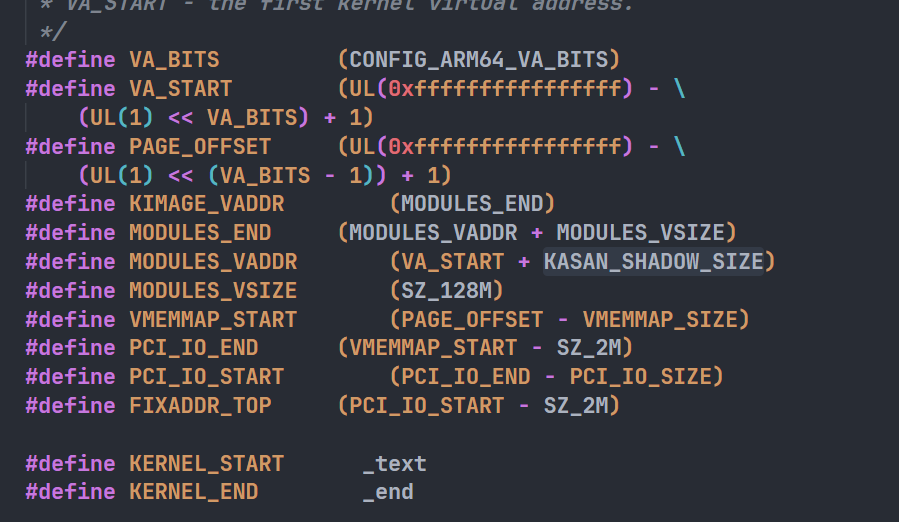
. = KIMAGE_VADDR + TEXT_OFFSET;
.head.text : {
_text = .;
HEAD_TEXT
}
.text : { /* Real text segment */
_stext = .; /* Text and read-only data */
__exception_text_start = .;
*(.exception.text)
__exception_text_end = .;
IRQENTRY_TEXT
SOFTIRQENTRY_TEXT
ENTRY_TEXT
TEXT_TEXT
SCHED_TEXT
CPUIDLE_TEXT
LOCK_TEXT
KPROBES_TEXT
HYPERVISOR_TEXT
IDMAP_TEXT
HIBERNATE_TEXT
TRAMP_TEXT
*(.fixup)
*(.gnu.warning)
. = ALIGN(16);
*(.got) /* Global offset table */
}
2. 内核启动第一阶段
2.1 内核启动入口点
我手上有一块迅为的RK3588的板子,我们来将编译好的vmlinux的elf文件读一下看一下入口地址是多少:
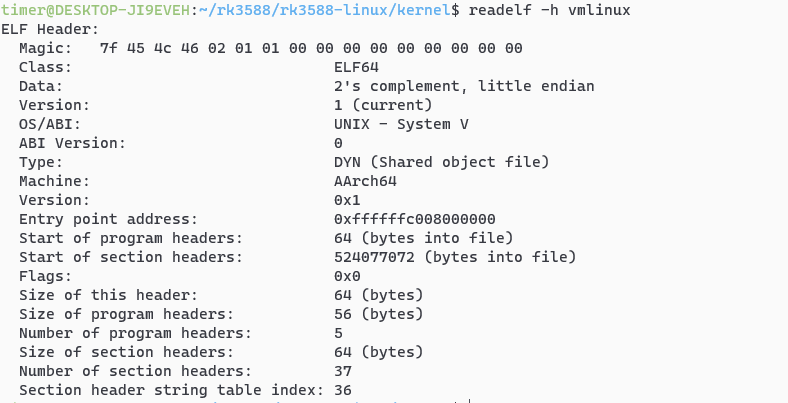
使用迅为提供的编译器将其反汇编,在得到的汇编文件vmlinux.s中查找入口地址:0xffffffc008000000
vmlinux: file format elf64-littleaarch64 |
由上面的反汇编文件可知,Linux内核的第一条指令是add x13, x18, #0x16,对应的符号是.head.text,在include/linux/init.h中有如下定义:
/* For assembly routines */ |
即__HEAD这个宏代表的就是.head.text这个段,所以去寻找__HEAD这个宏看哪里使用了,在arch/arm64/kernel/head.S中:
/* |
这里就是内核的启动点,在上面的注释中说了linux内核启动之前需要关闭MMU以及D-cache,I-cache可以开启或者关闭,同时x0为FDT blob的物理地址
D-cache是数据缓存I-cache是指令缓存FDT是uboot使用的扁平设备树,flatted device tree,
数据缓存有可能缓存了bootloader的数据,如果不清除,可能导致内核访问错误的数据。而bootloader的指令与内核指令无关,所以可以不关闭指令缓存。
add x13, x18, #0x16 用于形成 “MZ” 签名。主要是为了满足 UEFI 固件对映像文件格式的要求,而不是为了执行任何有意义的计算。其作用是确保生成的机器码包含必要的 “MZ” 签名,使得内核映像可以被 UEFI 识别和启动。相当于一个魔数。然后执行b primary_entry跳转到primary_entry函数执行:
2.2 primary_entry函数
__INIT |
primary_entry会依次执行preserve_boot_args、init_kernel_el、set_cpu_boot_mode_flag、__create_page_tables、__cpu_setup、__primary_switch
2.2.1 preserve_boot_args
/* |
boot_args定义在arch/arm64/setup.c中,用于保存内核启动时的参数,是一个数组/*
* The recorded values of x0 .. x3 upon kernel entry.
*/
u64 __cacheline_aligned boot_args[4];stp是一个存储配对指令,将两个寄存器的值存储到连续的内存位置。
2.2.2 init_kernel_el
/* |
这段代码实现了在不同异常级别(EL2 或 EL1)下对处理器进行初始化,并根据当前的启动级别设置相应的寄存器和状态,以便内核能够正确执行。主要步骤包括:
- 配置 EL1 的系统控制寄存器。
- 检查当前异常级别。
- 如果是 EL1
- 配置 PSTATE 和异常链接寄存器。
- 切换到 EL1 并继续执行。
- 如果是 EL2
- 配置 Hypervisor Configuration Register。
- 进一步初始化 EL2 状态。
- 设置异常向量基址。
- 切换到 EL2 并继续执行
2.2.3 set_cpu_boot_mode_flag
/* |
w0寄存器保存了cpu的启动模式__boot_cpu_mode是一个int64的全局变量保存cpu的启动模式,前面四个字节的值为0xe11,后面四个字节的值为0xe12
2.2.4 __create_page_tables
/* |
页表的映射比较复杂,后面再分析,主要是的功能时缓存无效化、页表清空、虚拟地址配置,然后把内核进行了映射。
2.2.5 __cpu_setup
//arch/arm64/mm/proc.S |
__cpu_setup定义在arch/arm64/mm/proc.S中,这段代码通过一系列步骤初始化处理器,以便安全地开启内存管理单元(MMU)。主要步骤包括:
- 无效化本地 TLB
- 启用浮点和 SIMD 单元
- 设置调试寄存器
- 配置内存属性寄存器
- 配置翻译控制寄存器和基址寄存器
- 设置物理地址大小和硬件访问标志
- 准备系统控制寄存器并返回
这些步骤确保处理器在启用 MMU 时能正确处理内存访问和管理
2.2.6 __primary_switch
SYM_FUNC_START_LOCAL(__primary_switch) |
这段代码主要是用于内核映射的重定位,如果内核地址需要重定位则需要查询页表进行重新映射,然后在最后
ldr x8, =__primary_switched |
跳转到__primary_switched函数继续执行
/* |
此函数在启用 MMU 后执行,负责初始化各种系统寄存器和数据结构,清空 BSS 段,处理设备树和特性覆盖,并根据需要处理内核地址空间布局随机化(KASLR)。最后,它跳转到 start_kernel 函数,开始内核的主要启动过程。
3. 内核启动第二阶段
Linux内核启动的第二阶段也就是常说的C语言阶段,从start_kernel()函数开始;start_kernel()函数是所有Linux平台进入系统内核初始化后的入口函数;主要完成剩余的与硬件平台相关的初始化工作,这些初始化操作,有的是公共的,有的是需要配置才会执行的;内核工作需要的模块的初始化依次被调用,如:内存管理、调度系统、异常处理等;
3.1 start_kernel
start_kernel()函数在init/main.c文件中,主要完成Linux子系统的初始化工作;
casmlinkage __visible void __init __no_sanitize_address start_kernel(void) |
可以看见依次调用了很多的初始化函数
参考链接
 微信
微信 支付宝
支付宝
![ARM64-Trust-Firmware[3]-BL1解析](/2026/01/24/ARM64-Trust-Firmware-3-BL1%E8%A7%A3%E6%9E%90/17692290470595.png)
![ARM64-Trust-Firmware[2]-启动ATF](/2026/01/24/ARM64-Trust-Firmware-2-%E5%90%AF%E5%8A%A8ATF/17692287555201.png)
![ARM64-Trust-Firmware[1]-ARM安全架构](/2026/01/24/ARM64-Trust-Firmware-1-ARM%E5%AE%89%E5%85%A8%E6%9E%B6%E6%9E%84/17692284856153.png)
![Xhyper剖析[6]--中断虚拟化](/2026/01/20/Xhyper%E5%89%96%E6%9E%90-6-%E4%B8%AD%E6%96%AD%E8%99%9A%E6%8B%9F%E5%8C%96/17689244713913.png)
![Xhyper剖析[5]--MMIO虚拟化](/2026/01/20/Xhyper%E5%89%96%E6%9E%90-5-MMIO%E8%99%9A%E6%8B%9F%E5%8C%96/17689243819381.png)